We need to be the historians of our own software
Codebases are peculiar things. They’re accumulators of debt and investments, warts and jewels. Over time, all the decisions–conscious and unconscious–made by a rotating cast of characters sum up to the current state of your main branch, HEAD. The HEAD may change every few minutes, hours or days. But as long as your codebase is alive, it’s changing.
While every codebase is in motion, some things are immutable (or change so slowly they feel that way). Software can have character and a sense of place, much like a city. And just like a city, the bones of a codebase are built with imperfect context and are adapted over generations, with mixed results.
When I close my eyes, the codebase I'm working on almost has a smell to it. If I were to go away away for a few years and come back, this codebase would be different, but still itself.

When you make a change to your codebase, you’re not starting from zero. Sometimes it can feel like you’re standing on the shoulders of giants. Other times it feels like those who came before you made foolish choices. Either way, they defined the semantic water you’re swimming in, and they’re more like you than you might think: human beings trying to make something makes sense with imperfect tools and imperfect craft.
If we want to influence the future of our software–to make it a better place to live and work in–we need to understand where it came from. We need to understand the human story of how we got from the first commit to HEAD. We need history.
When it comes to historical tools, we have a lot, actually. Git in particular comes to mind as an asset. Git is like an archival record of every little change over time. It can answer specific questions and contains many treasures if you take the time to look. For example, if you’re wondering how a file came to be, git has a lot to say, especially if there are commonly good PR descriptions in your project.

But it’s really hard to contextualize a long series of git commits. You can’t zoom out and understand the the world around the code. In 2012, what did the app feel like from the point of view of a user? What did the codebase feel like from the point of view of the engineers? Try checking out a historical commit and running it–If it’s even possible, it’s not fun or practical. Beyond the software itself, the human stories are totally out of reach. What was on the minds of the engineers? What were their struggles? Their triumphs?
Depending on the age of your project, you may be able to speak with some people you see in the git blame. You should. You should ask them questions and write down what they remember. It’s gold. But, that’s not enough. Gray matter is an imperfect storage medium. Memories fade. You’re not talking to the version of your colleague who just made a decisions, you’re talking to the person who has the benefit of hindsight. It’s not possible for them to reconstruct their cognitive state. Even if it were, you’d just be talking to one person. Most of the team has turned over.
We would benefit from tools we don’t have
If we really want to understand the codebases we work in, we need better tools to construct the history. We need software to sift through git. I want to know how the quantities of certain types of code changed over time. I want to know when one style came into the codebase, plateaued and then declined. I want to understand trends.
But beyond git, we need to understand the people. How did teams and team members change over time? What were they trying to do, in their own words? where did they think they were going? What was contentious? What was going on in the business? What was going on in the world?

There are many other artifacts that are not in git. Businesses always have a large set of documents in some kind of wiki or docs editor. They usually have author attribution and a big set of hyperlinks to other artifacts. This web is dense. The authors are very present-minded. They don’t include a lot for future readers.
In the last 18 months, it’s gotten a lot easier to automatically summarize documents. We should be using Generative AI to make these artifacts easier to use.
I want a timeline view of a project’s history. I want to be able to pan and zoom. I want to go to different points in time and see product demos from the teams that worked on it. I want to have links to various documents with well picked excerpts. I want summaries. I want to understand quarter-by-quarter what the people were trying to achieve. I want to see when people joined and when they left.
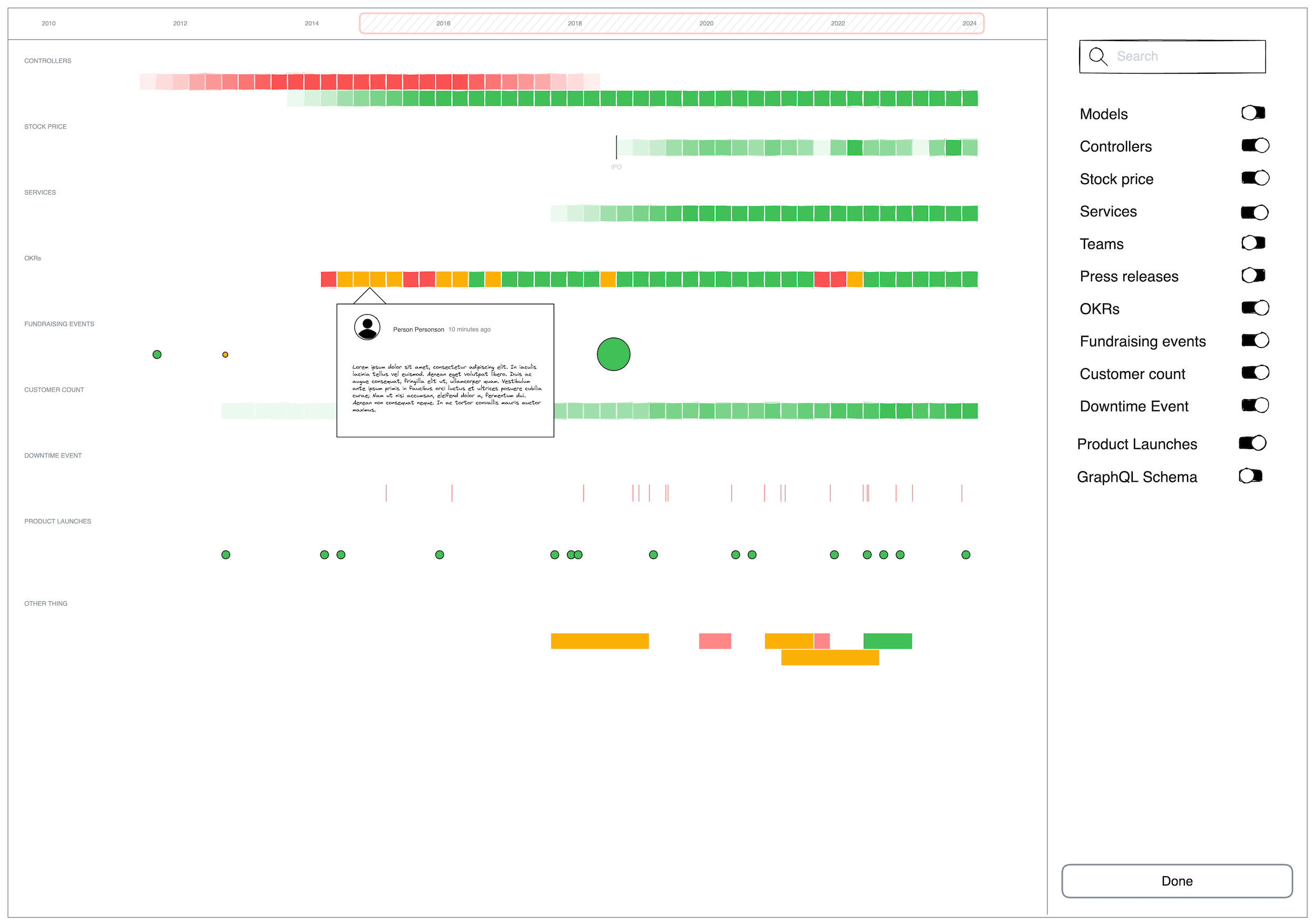
Ultimately making history is an act of synthesis. What I’m picturing in my head isn’t the history itself, it’s a tool to make the history easier to distill. It would make a great deal of data about the past something that the whole team can understand and benefit from.
History can provoke hard, necessary conversations
Just like every other historical endeavor, constructing a narrative of the past can provoke difficult conversations. Why did we suddenly change all our engineering practices in 2015? Oh it’s because the whole team quit when the VPE was fired. Woah. Ouch. Why did we go all-in on technology? Oh, it’s because person (who may still work here or know people who does!) thought it was a great idea.
In order to make this endeavor useful you need to adopt a nonjudgmental mindset. You should assume that the people who built this codebase were making the best decisions they could with the tools and information they had at the time. You may feel like better decisions are obvious, but you’re benefiting from information they didn’t have.
And, sometimes these difficult conversations are necessary. Sometimes in order to move forward we have to be open about what really happened, and own it. History isn’t always rosy, and that’s OK.
People already have narratives of the past, they're just not always backed by data
Humans make narratives like spiders make webs. Everyone in your organization has a story they tell themselves about the past. Someone might think "oh quality really dipped as we focused on growth pre-IPO" or "we really sped up when we got our new CTO" for example. But did these things really happen? These narratives reflect an individuals lived experience, and we shouldn't discount that. But can we observe anything empirical?
It's absolutely possible to over-index on empirical data... and it's important to be mindful of that. But empirical data, when it is high quality, can help us zoom out and show a larger perspective than one individual on one team. It can mitigate fuzzy memories and group-think. It can show how parts of a system interacted over time. It can help us learn from the past, correct misconceptions, and make us overall better at whatever it is we're trying to do.
You can make it easier for future historians (yourself?)
Tomorrow's history is now. You an do things now that will make life easier for future historians. At work we have a repo called artifacts which contains all sorts of runtime artifacts that would be difficult for us to reconstruct later without the app running. As an example, we have an artifact that gives us details about our ActiveRecord models. We know for each commit how many public instance methods existed any given model, or what AR associations and scopes were defined. We also know what Packwerk pack each model is associated with, and which team is the owner. For our Packwerk modules, we know each of their "modularity scores"–an in-house metric.

These artifacts are tracked in git and are updated in a "shadow repo" every time our monolith builds. This means we can see how they change over time. We've had some of these artifacts for 8 months, and they've proven invaluable.
But we could be doing more. We could be conducting interviews. We could be journaling. We could be proactively making the lives of future historians easier, and we should.