Div III: Empowerment software
The following is a summary of my 2013 senior thesis at Hampshire college. Many of the themes I identified at the time still resonate with me, so I decided to include it in my blog. Some of it I roll my eyes at, but that's OK.
Introduction
Picking a Div III
My Div III started twelve months ago. I was looking for a large-scale project to create or join. I was considering a lab-based biology research project. But, I felt that that sort of project wouldn't play to my strengths. I was attending a Biomath lecture series at Smith College. The purpose was to present the complex intersection of computational techniques and life sciences. It was also intended to encourage young people to work with computational and biological fields. At the time, I was TA-ing Organic Chemistry (it had been my third semester of chemistry in a row). I didn't want to be a chemist. I wanted to be a doctor, and I had to study chemistry to go to medical school. Nonetheless, chemistry was interesting, and it was becoming less intimidating than it had been the year before.
I heard a lecture on Genetic Programming by Lee Spector. The talk was fascinating. He described how one could create a computer system where programs evolved to solve problems. It had been my first formal introduction to GP. During the talk, I remembered a conversation I had had with my friend Omri Bernstein. He was telling me about how he thought there was probably an interesting project that would combine Genetic Programming and Organic Chemistry. In the QA of Lee's talk, I raised my hand, "Has anyone ever combined GP and organic chemistry." He said that he hadn't heard of anyone doing that, but suggested that I meet with him and talk about it.
I considered doing a Div III in that subject area. GP and chemistry seemed to leverage my strength in computer programming in ways that an ambiguous biology project wouldn't.
I met with Lee a few times, once with a Smith chemist, David Gorin. Lee described GP to Dave. Dave thought of a project that might work. I was seriously considering doing the project.
Then, the biomath lecturer coordinator announced that students could apply for an NSF-funded Biomathmatics fellowship. I decided to apply with this project. If I was accepted, I would make this my Div III. I was, and I did... at least at first.
The Summer
Before the Biomath fellowship, I had arranged an internship at the Center for Resuscitation Science at Beth Israel Deaconess Medical Center in Boston. Now that I had the fellowship, I would have to juggle both. But, I didn't yet know what my responsibilities at BIDMC were. Lee and the fellowship coordinator agreed that it would be OK if I were to travel to the 5 college area weekly for meetings. Luckily for me, the job at BIDMC was pretty rote. I had to do a lot of manual data entry. I had no ongoing projects. They were fine with me working 3 days per week. I worked Monday, Tuesday, and Wednesday. On Thursday I would take the bus to Hampshire and attend a meeting with Lee and his research students. I stayed on a friend's couch and bussed back the next day.
With Lee's group, my first task was to build the data infrastructure that would allow for the chemistry GP project. I was dealing with data from all sorts of different sources, building a database that would be easily accessed by GP. This project is described in the ChemGP section. At the same time, I was doing very repetitive work copying data from one computer system to another in the hospital. I realized that I had the technical tools to improve the BIDMC computer systems used for research. But, no one at BIDMC was willing to entertain the idea. In August, I wrote an essay about my experiences and frustrations with clinical research. After many iterations, this piece will be published in The Scientist in May.
The fall
In the fall, I was working on my Div III while doing three advanced learning activities. I was teaching Intro to Web Development, TAing Organic Chemistry II, and TAing Genetic Programming. The largest commitment by far was teaching Web Development. I planned the classes, reviewed student work, and met with students. TAing Orgo was less work, but still took time. I had weekly TA sessions, went to class, reviewed material, and met with struggling students for extra help. TAing Genetic Programming was my smallest commitment. I went to class and occasionally met with students who needed help.
By the end of October, I had made some progress on my Div III project. I had built WebGP (described below) and interfaced ChemGP with it to do runs. It was around this time that I went to a Hackathon hosted by Communicate Health at UMass. My team produced CarrotStick (described below). We won the Hackathon. That project started to change my priorities. Building software that related to people was very exciting.
A few weeks later, the team went to another Hackathon. This one was hosted by Mass General Hospital and MIT's Hacking Medicine group. The subject was Global Health. We built Trext (described below) and received a second-place prize. Trext became the largest part of my Div III. I worked on Trext full time (+ 50%) for several months.
As the technical demands of Trext plateaued (while I waited for the business aspects caught up), I started working on Modfinder, a tool to help Hampshire students find housemates. The impetus behind the project was primarily to learn a new technology stack. The project is described below.
Throughout my Div III, I collaborated with different individuals. On ChemGP, I worked with Omri Bernstein, especially in the beginning. The opinion essay I wrote was co-authored with Dr. Martina Steurer, MD, although I did the primary writing. On CarrotStick, I collaborated a lot with Kira McCoy, and somewhat with James Matheson and Amit Ringel. I worked on Modfinder with Seth Toles.
My preferred technology stack for web apps has changed significantly over the course of the year, mostly on the server side. I started the year working primarily with PHP/MySQL. Now I prefer Node.js, MySQL, and MongoDB.
webGP
webGP is a web-based, javascript tool that allows anyone to do symbolic regression GP runs.
What is GP
Genetic programming is a technique that allows computers to write programs. The genetic programmer must first write a function that can evaluate program-candidates. This is called the fitness function. This function evaluates a candidate program and returns some form of score. The genetic programmer must also build a random code generator that can produce random programs. With these two components, one can build the first steps of a GP system by generating many random programs and evaluating them with the fitness function. Typically, none of the random programs come close to a good score, but some are better than others. Thus far, this is mildly interesting, but not powerful. In order to leverage principles of Darwinian evolution, programs must be able to "reproduce."
A simple genetic programming system is completed when programs can mutate and/or breed with one another. A mutate function takes a program and returns a modified version of that program. A crossover function takes two programs, removes a piece of one, and replaces it with a piece of the other. To run the finished GP system, generate a series of random programs. Rate their fitnesses. Pick some of the better programs and breed them to produce a new series. Each series is called a generation. If the system is working properly, the programs' fitness should improve over time.
Genetic programming is a deep and rich field. There are countless papers published on variations of each of the concepts explained above.
What is Symbolic Regression
Symbolic regression is a GP technique that attempts mathematically explain data. In some ways, it is analogous to linear regression. In linear regression, two-dimensional (x, y) data is modeled by a linear function. Symbolic regression is similar except there are no requirements on the type of function and the data can be n-dimensional (x, y, z, ...). Functions are generated through GP. Symbolic regression is powerful when searching through complex data.
Motivation
As scientific tests become less expensive and more abundant, scientists are facing increasingly large datasets (source). Symbolic regression has potential as a tool for scientists to make sense of the mess they're in. But, it faces a problem. The barrier to entry is too high. This was the inspiration for building webGP. I wanted to give people a way to run GP on data they have sitting in an excel file or database.
Function choice and GP parameters
Function choices and GP parameters. I made an interface that allows the user to decide what mathematical operations the evolved programs may employ. The user can also specify parameters about the run (its length, size of generations, etc).
Visualization of results
- Real time
- Visualizing the best error in each generation as the data comes in
- Visualizing the best program's size as it is generated
- After the run
- Best program's predictions against fitness cases. A graph that plots two series. The fitness cases and the best program's prediction of what they should be. This gives the user a rough understanding of how good the best program is.
- Piano plot. This graph shows each individual program's score plotted on the y-axis and its (arbitrary) ID on the x-axis. The IDs are based on score and generation. Each point is shaded based on its length. This plot can give the user a sense of the diversity of the population in each generation
- Size vs error vs age. This graph shows how the relationship between size of programs, their error, and their generation. It gives the user a sense of how size and error changed over generation time.
Process of building
At first, I started building a simple GP engine in javascript as a way of learning GP. I had been working on other projects in Clojure, but didn't have a good feel of the language. I didn't want to let this technical clumsiness inhibit my learning of GP. Once I had the engine working, I realized how easy it would be to make a web front-end. First, I just made the data table and GP options. Then, I wanted to see how the process was going in real time. I started learning D3.js, a graphing library. I made some classes for bar charts and scatterplots--the two types of visualization I eventually wanted. With those classes, I made some powerful graphs.
Challenges
When webGP is used for small problems, it's great. Chrome's V8 javascript engine is lightning fast, and webGP is written well enough to harness its speed. But, because I wrote webGP to store and analyze every program ever produced by GP, it eats up a lot of RAM. If you have many generations, and each one is very large, it crashes the browser tab. Also, some of the visualization techniques performed after the run need to output a point for every program. This can take some time. I did make a modification to have the scatterplots only reflect a representative sample of the population. This improved speed considerably.
What would come next
To mitigate the memory problem, I would send the programs to a node.js server to be stored. Node.js has the capacity for real-time client-server interaction with the use of websockets. This means once programs are created and evaluated, they can be stored elsewhere. This frees the client to run as long as it needs to. It also opens up the door for multiple computers all running the same problem.
Status
This project is open source and on GitHub.
ChemGP
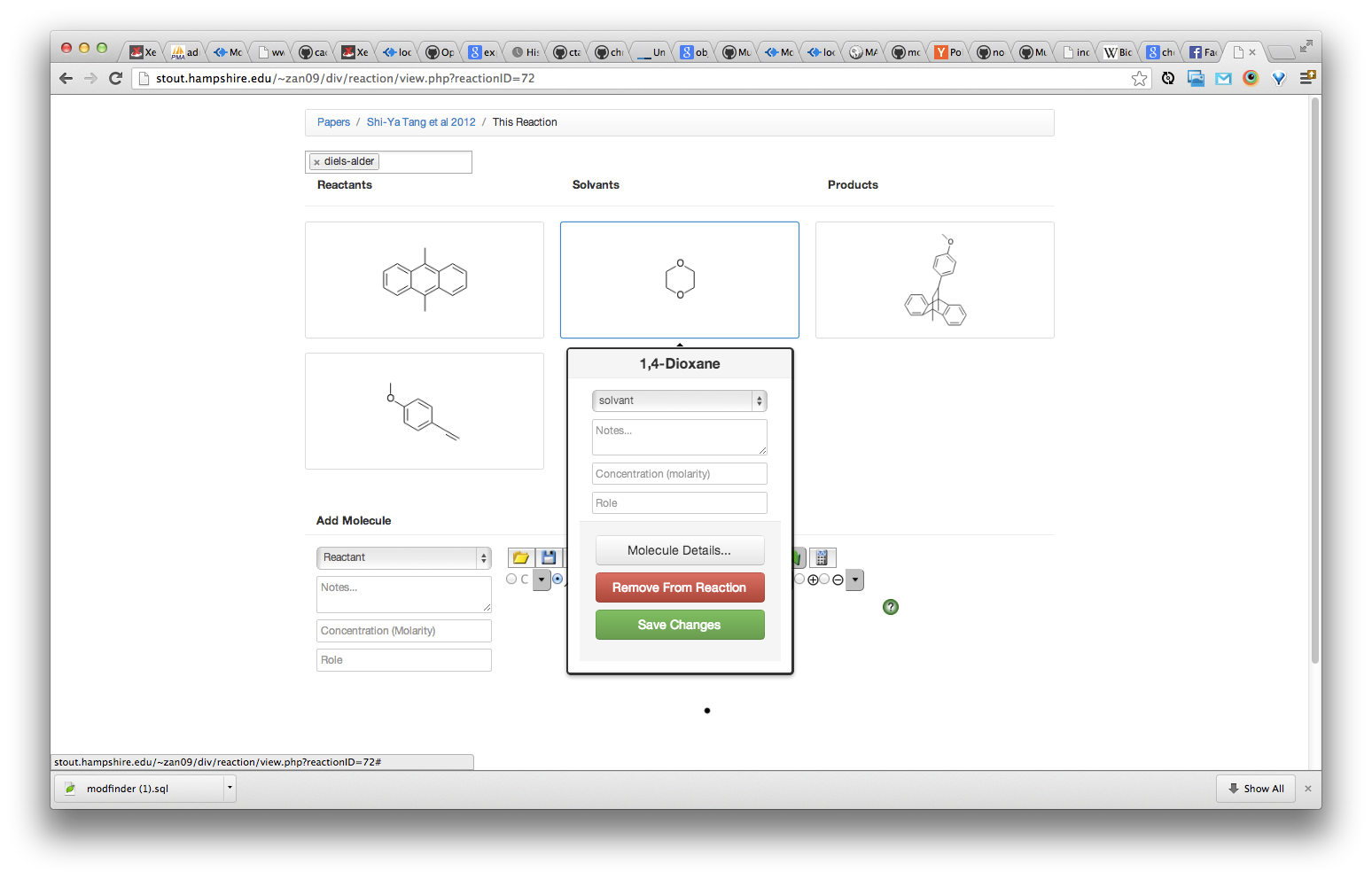
In this project, I sought to find mathematical relationships between several attributes of molecules and their reaction rate constant in a cycloaddition reaction. I used symbolic regression GP in the search. Cycloadditions are reactions that make a new hydrocarbon ring (or "cycle"). They are synthetically powerful for many reasons, but here I will focus on their utility in "bioorthogonal" chemistry (BC). BC is the study of synthetic chemical reactions that run inside an organism but do not interfere with the endogenous biochemical reactions. Applications of BC include attaching fluorescent molecules to proteins without the standard transgenic mutations required for the technique. These "tagging" reactions could be used by biologists or clinicians for diagnostic purposes. Bioorthogonal chemistry might one day be used for therapeutic purposes.
In order to be useful, BCs must adhere to a rather stringent set of requirements. They must react selectively (have little to no side reactions). They must not be cytotoxic (deadly to the tissue or organism). They must be kinetically accessible (they must happen quickly enough and in high enough yield to be measured). Many of the synthetic techniques used by organic chemists require there to be no water in the reaction. BC reactions must run in water. Organic chemists can control the temperature, pressure, and pH of their reactions, BC reactions must be under physiological conditions. These criteria make BC reactants hard to find.
In this project, I used symbolic regression GP to search for a mathematical relationship between known properties of BC cycloadditions and their reaction rate constants (k). In order to start with GP, I had to build a significant amount of cheminformatic infrastructure. Essentially, I needed a database of reactions. I needed many parameters about each molecule in the reaction--two reactants, a solvent, and a product. I also needed information about the reaction (its pressure, temperature, reaction rate).
I built the database with PHP/MySQL and javascript. I employed the Chemdoodle web framework, an HTML 5/javascript chemistry toolkit. They have an API service which was purchased for chemical computations. Using Chemdoodle, I manually drew dozens of reactions from two papers and entered the reaction parameters. Chemdoodle's API calculated parameters for each molecule and I wrote code to save these calculations into MySQL.
In order to get the data in a format that allowed webGP to be used, I needed to write code to translate the multidimensional MySQL data into a linear list. Each reaction consisted of four molecule rows, one reaction row, and several rows to indicate the relationship. Each row had up to 16 fields. I had to translate this information into a simple list. To do this I prefixed all molecule data with the role it was playing in the reaction (diene-molecular weight, dieneophile molecular weight, solvent molecular weight, etc). From this, I was able to create a simple table representing all the data. From this I used webGP to generate functions that took every reaction variable and generated the reaction rate constant.
I found that the webGP engine that had worked well for simple problems was not effective with this problem. The programs evolved but plateaued early in the run (they did not continue to improve). In order to improve the GP performance, I patched webGP to include "trivial geography" in the mating functions. This technique selects the most fit programs from each area in the population, not the population at large. This allows for slightly less fit programs to survive longer and preserves diversity in the population.
The implementation of trivial geography made the runs' plateaus come later, and their fitnesses improve.
I also needed to modify the code to include separate data categories for training and validation of the programs. Certain reactions were randomly selected to train (be used in the fitness evaluation) while others were left to evaluate the fitness of the best programs from the run. Because these data were not used in the training, their incorporation reduces the degree to which the evolved programs are biased towards the dataset.
I presented this project at a 4CBC event in November 2012. The slides from this presentation are available here.
Status: This project is open source and on GitHub.
CarrotStick
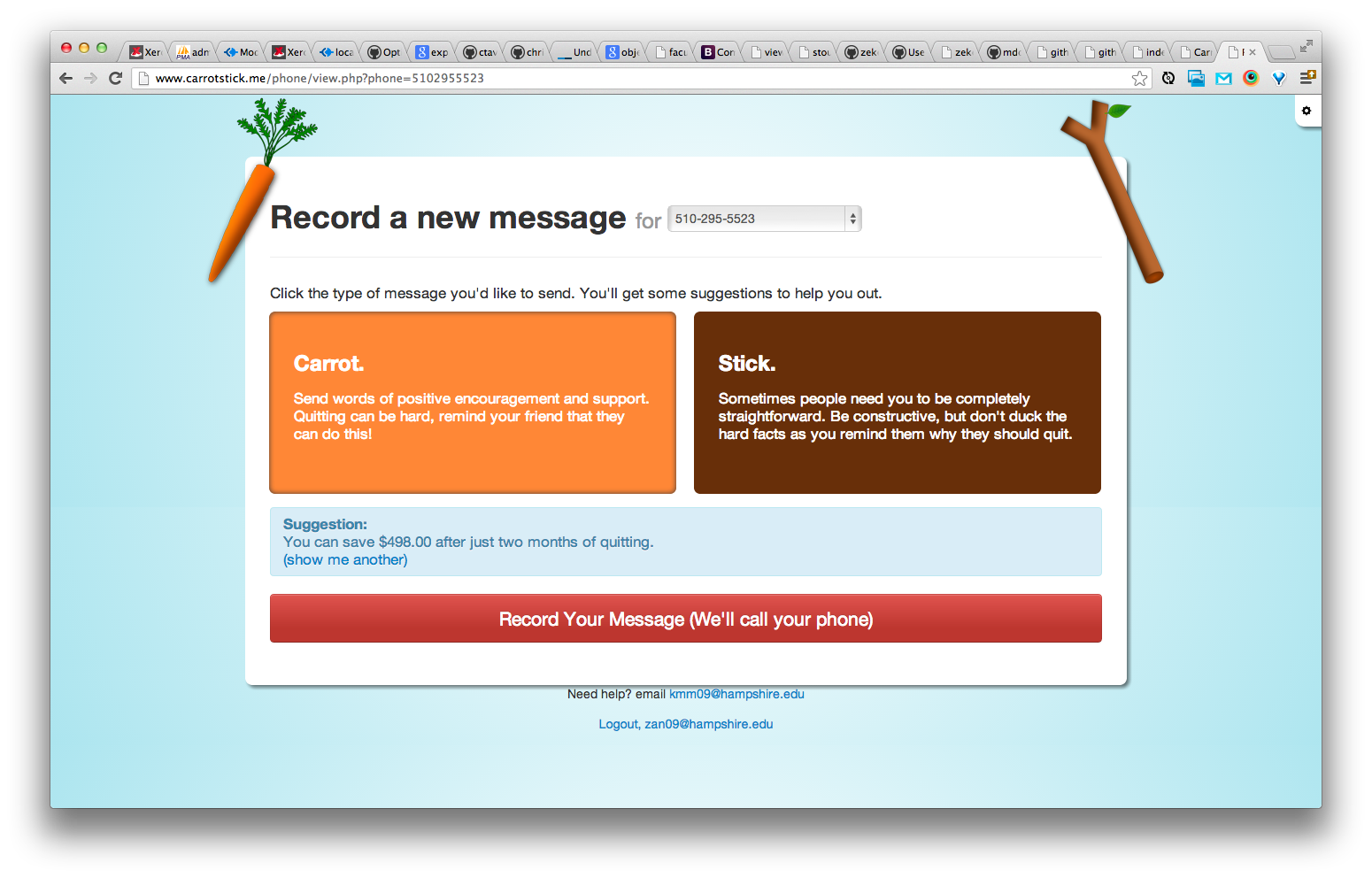
Carrot Stick is a piece of web software written at a hackathon hosted by Communicate Health last fall. We were tasked with writing software that helped communicate public health messages. A team of four (myself, James Matheson, Kira McCoy, and Amit Ringel) worked for two days to produce Carrot Stick.
The abstract from Kira McCoy's Div III:
Smoking is the leading cause of preventable death in the US (Danaei, Ding et al. 2009), and accounts for 1 in 10 deaths worldwide (Park, Tudiver et al. 2012). Information is not enough to change behavior. Many smoking cessation interventions have harnessed the power of social relationships, however none have provided direct messages in loved ones' voices. The literature shows that "The person-to-person spread of smoking cessation appears to have been a factor in the population level decline in smoking seen in recent decades" (Christakis and Fowler 2008). People are connected, as is their health. Social relationships and expanded agency can be used to help people achieve health goals like smoking cessation. Services such as counseling may have short-term impacts on smoking habits, but concern from a loved one may have lasting effects.
A feasibility study of the program "CarrotStick" was conducted to assess a novel smoking cessation intervention. CarrotStick empowers smokers to quit by providing unique support from family and friends. A smoker signs up online, invites friends to record messages and when she feels the urge, calls a number and hears either a "carrot message" (positive reinforcement) or a "stick" (tough love). Participants were smokers over the age of 18, who have the intention to quit. They were recruited through posters and online advertisements, leading them to the study website. Participants completed three surveys throughout the intervention, assessing smoking behavior, satisfaction with CarrotStick and other feasibility items.
The results being analyzed include assessing the number of recorded messages, types of messages, frequency of listening, attrition rates, impacts of reminders, software satisfaction, and limited smoking cessation efficacy.
This study will provide insight into the impact and feasibility of implementing CarrotStick on a larger scale.
Carrot Stick was unanimously chosen by the judges to receive the top prize. Our group was elated. We were surprised by the degree to which our collaboration had improved our final product. We were all surprised by how good Carrot Stick looked after just two days.
Kira decided to keep working. She changed her Div III. She wanted to run a feasibility study on real smokers to see if Carrot Stick really helped people. To do this, I had to do some ongoing work. I built out different views for the app for participants in the control group and participants in the treatment group. I also designed and developed a survey form that combined three tobacco dependence measurements that Kira found. Finally, after noticing that people forgot to call into Carrot Stick, I made an SMS reminder system.
Carrot Stick was built with PHP, MySQL, the Twilio voice API, jQuery, and underscore.js. It was deployed on the PaaS Heroku. It was the first time I deployed on a PaaS.
Status: The status of this project is unclear. We may continue development with grant money in the fall. If we don't, we will open-source the project.
Trext

After our group's success in the first Hackathon, we decided to try again. We heard about Hacking Medicine, an event at Massachusetts General Hospital hosted by the Massachusetts Institute of Technology. The event's theme was global health. They were looking for groups to build software or hardware that could have an impact globally.
Before the event, we brainstormed for our idea. On our mind was the concept of the clinical checklist as presented by Dr. Atul Gawande, author of The Checklist Manifesto.
Dr. Gawande, a surgeon at Brigham and Women's hospital describes how two-minute checklists before certain procedures and operations can cut complications and death by double-digit percentages. As medicine's complexity has increased so have routine errors. Even experts with tens of thousands of hours of training make simple mistakes when confronted with complex, time-sensitive choices. Checklists can ensure that routine precautions are always observed in clinical settings.
Also on our minds was the limited technology in many low and middle-income countries. Building a web app for checklists was tempting, but our target populations don't have reliable or fast internet. However, some technology has penetrated nearly the entire planet. Most people have access to cell phones with SMS, for example.
We thought about building an SMS checklist builder. It would be great for data collection and updating checklists in a way that paper wouldn't. But, SMS is cumbersome, especially on older phones. One of Dr. Gawande's two-minute checklists might take 4 or 6 minutes by text. More importantly, some of the questions weren't relevant.
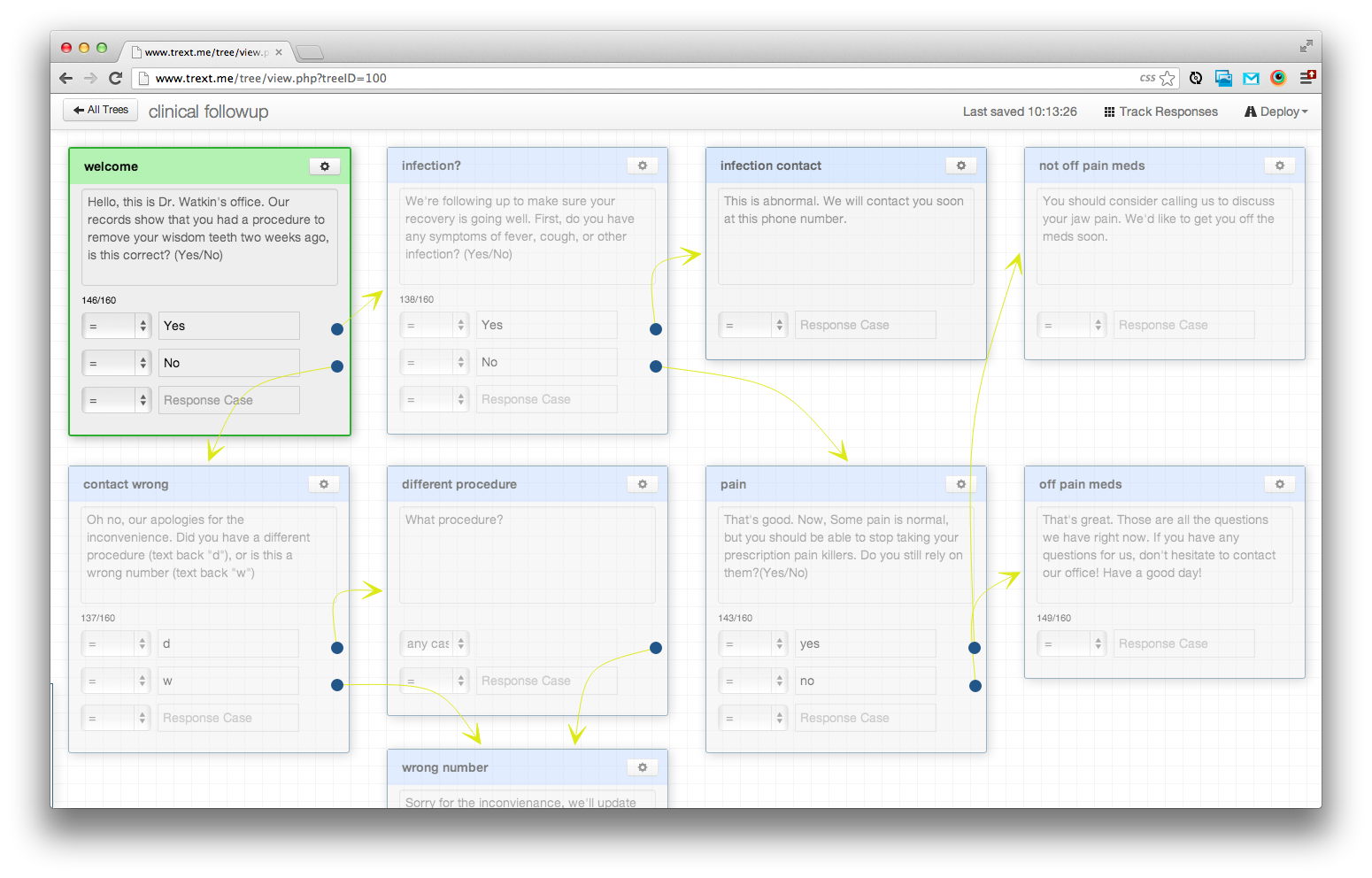
We stumbled on the idea of using the format of a decision tree to build these checklists. Decision trees can achieve complexity with a short path by eliminating irrelevant questions. We envisioned a simple GUI that would allow basic computer users to build SMS text apps.
At the event, we used a javascript library called JSPlumb as the backbone of our interface. On the server side, we used PHP and MySQL. The SMS functionality was achieved with the Twilio SMS API. It was an ambitious project for a two-day competition. But, 30 minutes before our presentation, we had a working prototype. For the presentation, we represented a clinical protocol for resuscitating infants. Our presentation could only be three minutes long so everything had to be condensed. We won one of the 2nd place prizes at the competition.
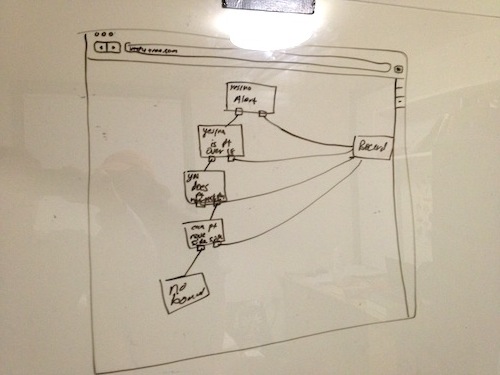
The software 2 days after the competition:
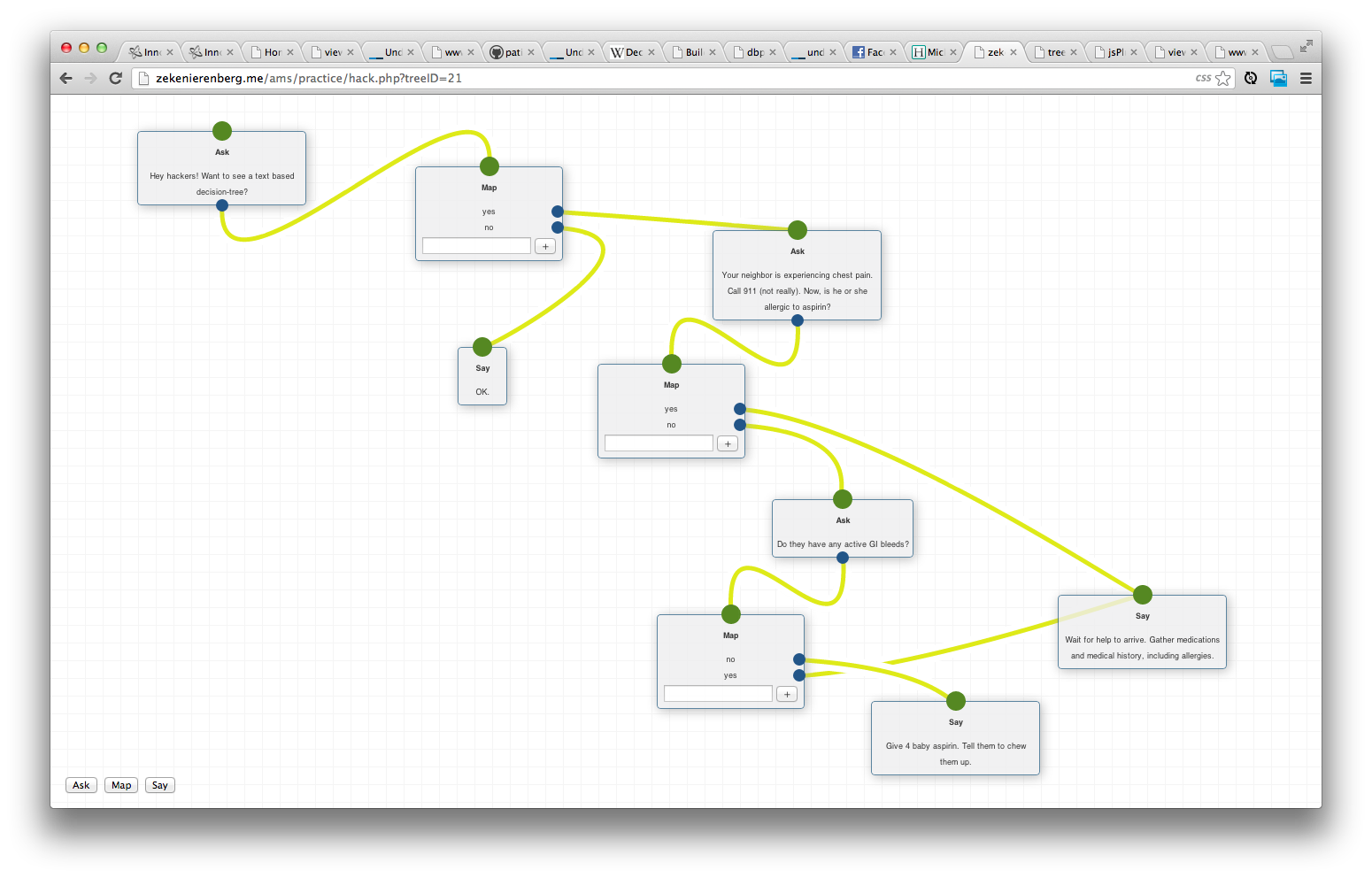
There was a palpable feeling that we were really good at this. We wanted to keep going. We thought the texting app was fantastic and we wanted to see it used on the ground in global health settings. But, everyone we showed it to had different ideas of use cases. Most of them were not in the field of global health. We realized we had built a useful design tool.
We thought about using the tool we'd created as a commercial product. But, before we could, we needed to rewrite the entire codebase. The hackathon code wasn't thought out very well and couldn't support new features. We wanted to use Node.js on the server side because of some of its advantages over PHP. But, node is hard to use. We had a lot of interest in the software, and we didn't have time to learn an entirely new technology stack. So, we took on some technical debt. We did a rewrite with the same technology stack. Much of the rewrite happened over winter break while I was shopping the idea around to VCs, talking to lawyers, and pitching to San Francisco-based leads.
The team worked intensely over January. We worked on a batch texting, or "Phonebook" feature in which trees could be started by our clients not the end-users. But, one client wanted to be able to reference information about the end-user in trees. They wanted to say something like, "Hey Zeke, we haven't heard from you in a while, how's the [insert x y or z] going?" We thought about creating certain fields that we could know about each user (name, email, etc), but realized that our different client bases wanted radically different things. Creating rigid fields wouldn't be consistent with what we'd already built: a design tool. We decided that any contact should be able to have n fields associated with this. We had been using the standard relational database: MySQL. We decided to employ a NoSQL environment without strict schemas.
But, we were slightly stuck. We didn't know how to graphically display very abstract, open-ended data. The solution came when we realized how our users would actually import contact data: an excel file. Our users have existing lists of the people they want to text, we just need to give them a way to upload them and view that excel file online. Here's a snapshot of how the Phonebook works with the tree builder.
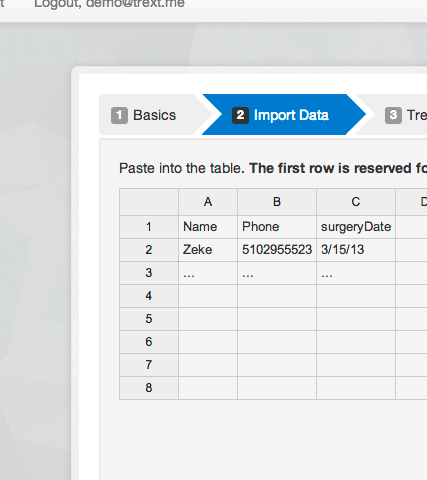
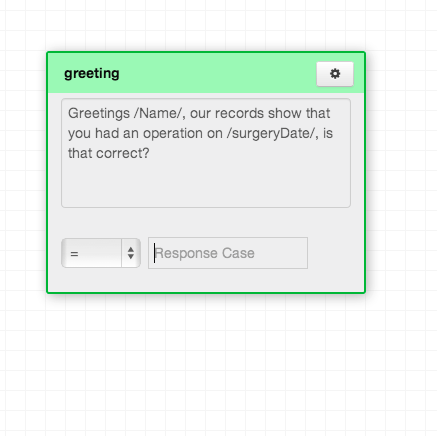
In February, we refactored the code three times. The third refactor was separating the code that ran trees on phones with the code base that built trees. They are truly different programs and it made sense to run them in different environments so they could be scaled appropriately. (We also realize that the phonebook can and should be separated. That way we'll be able to expose it as a commercial API someday.) We also rewrote the way conversations were stored. We realized that storing them in MySQL required a lot of processing every time a tree log was rendered. We started storing the logs in MongoDB and cut processing time significantly. In this time we also designed a marketing site.
Here is a screenshot of the Trext builder today:
We are currently working on rewriting the Trext SMS program in Node.js. The program that sends and receives SMSs is a perfect candidate for Node. Its IO intensive and would benefit from persistent connections to the database. Additionally, we may want to use websockets in the future to give real-time feedback about tree performance.
The TrextNode project is fully functional, but less tested than the PHP version. After it has been tested and transitioned into use, we will rewrite the backend of the tree builder and web app in Node for a consistent technology stack.
Future of Trext
Trext is going to be a company. We have three investors that are going to support us for a time, and we hope to get enough revenue to be sustainable soon.
Trext also has a future in global health and service. But, it is going to take some very different development. I don't want to get into business models, mostly because I'm not a business person, but I know enough to say that the Trext service isn't affordable enough for global health organizations. We have fixed material costs somewhere between 1.5 and 2 cents per text message.
Additionally, our text messages must come from the United States. This price and restriction makes no sense for a rural clinic in Haiti or Rwanda. However, I'm working on a solution to these problems.
USB GSM Modems (that are AT command compatible) can send and receive text messages from computers. Node.js can send and receive data from USB ports. Theoretically, a computer could be configured as a trext server that does the texting internally. Technically, it wouldn't even need an internet connection, just cell service. If the computer were a laptop, reliable electricity wouldn't be necessary.
To prototype the concept, I purchased a Samsung/Google Chromebook. I rigged it to run Ubuntu Linux from a standard SD camera card. I then configured the system with Git, Node.js, MySQL, and MongoDB. This process took a whole week, which was surprising. At every point in the configuration, I faced new and unexpected problems. I had never compiled C source code for example. I had cryptic errors all the time. When I ran the 'make' command, I got "error (2)." Google was surprisingly unhelpful. Eventually, I found that the problem had been in the system's locale settings. Throughout the process, I got a lot better at manual system configuration and learned that package managers are my friend.
Once I had the baseline system configured to my liking, I learned how to make a disk image with the dd command. I can now replicate the system onto new camera cards for new Chromebooks. The system is scalable. Its total cost is about $350. It runs Trext but could also work as a local web server for other services.
I'm currently working on adapting Trext to run on the system. I haven't yet purchased the GSM modem or begun that side of development, mostly due to cash flow problems. But I expect to be able to make the purchase next week.
After graduation, I have plans to take two prototypes to Haiti and meet my friend Jean. Jean works for OurSoil. They want to test our system. They will use it for following up on trainings they run, sending out surveys, reminders, and educational information. If the test run goes well, we could easily replicate these systems and send them elsewhere.
Status: Code is owned by Trext, Inc.
Modfinder
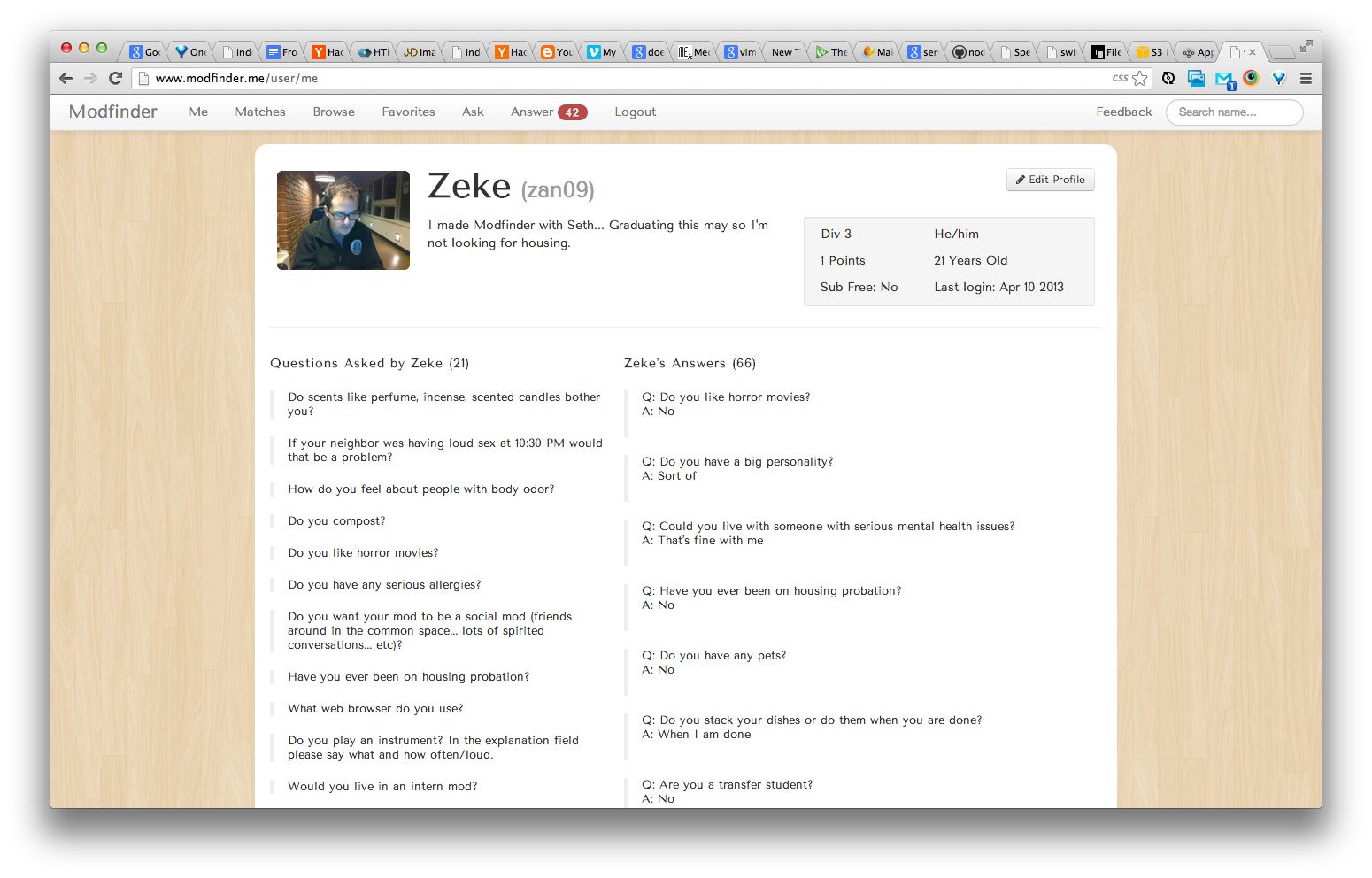
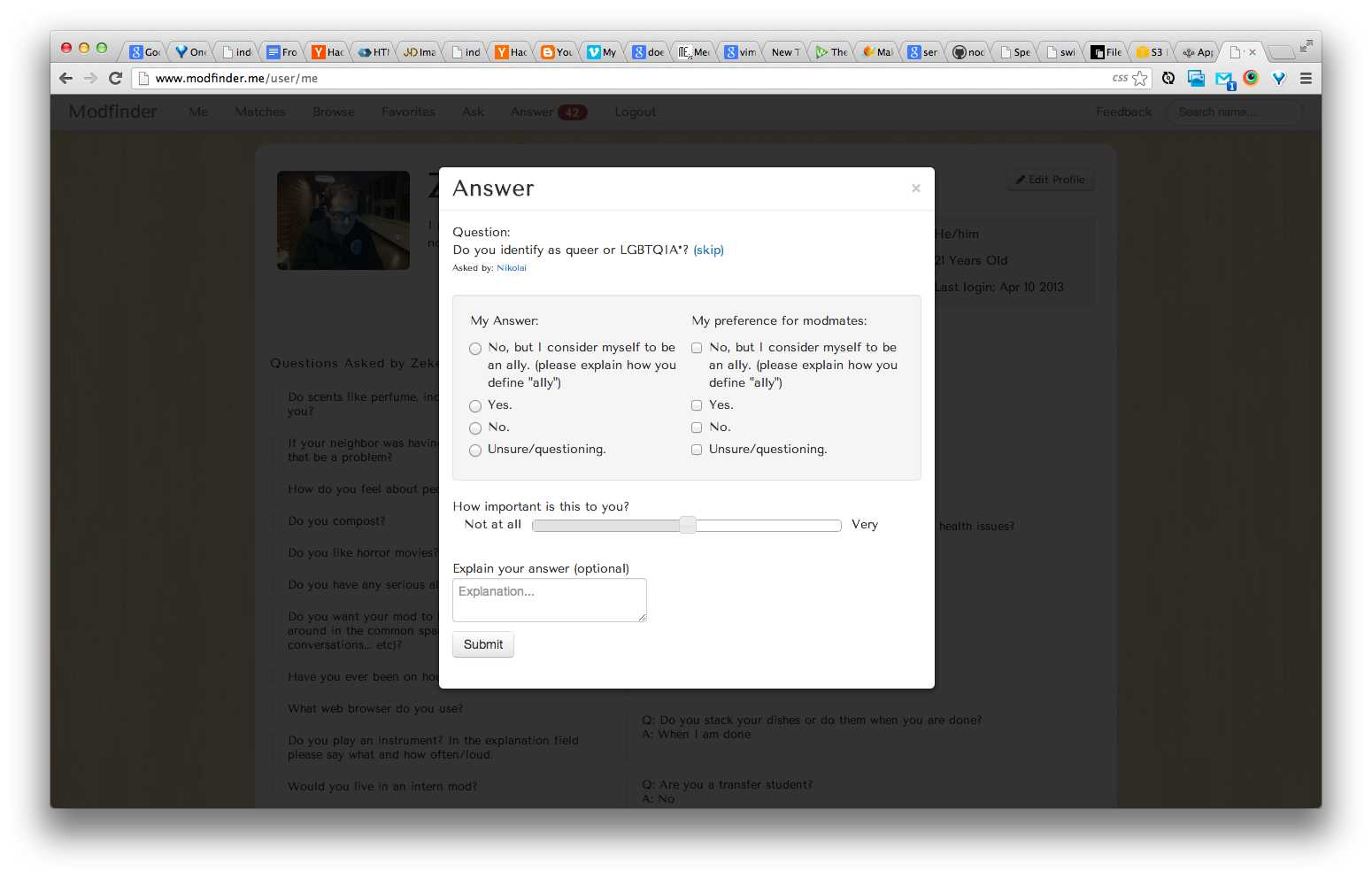
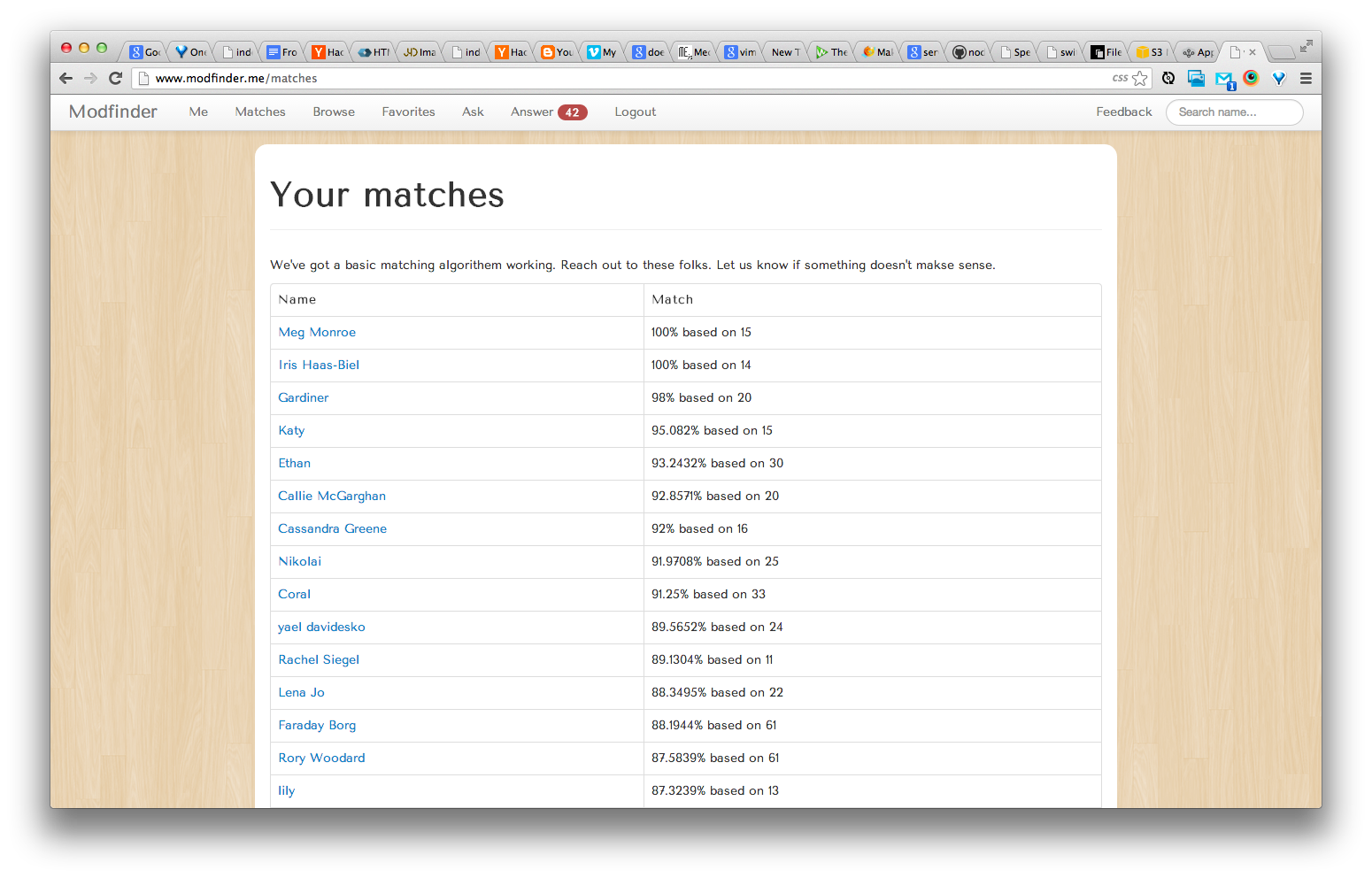
In February I went to EcoHackSF with Seth Toles and others. We built a cool toy, but nothing to showcase here. While we were there we talked a lot about web technologies. We both felt that we took shortcuts frequently while building websites. We wanted to "do it right" for once. We picked the most talked-about new web platform, Node.js. We decided to do a project in Node to learn it. After some brainstorming we decided to build a tool to help Hampshire students find mod-mates. We decided to model our service off the popular dating service OK Cupid. OK Cupid works by letting users ask questions to the entire community and answer others' questions. Users can answer the questions and also express the answer they accept in a partner. We outlined a plan to develop a similar platform. But, our platform would focus more on groups than on pairs. This is because group dynamics are much more complex than one-to-one relationships. You can think about an eight-person mod as a complete graph with eight nodes and 28 edges. There are 28 separate relationships in that mod. We wanted to do all we could to give people a good indicator about what they disagreed on.
First, to see if there was interest, we put up a simple site explaining the idea. In 24 hours we had signups from 20% of the population that participates in the housing lottery. We considered this a success and built the service over spring break.
Since the site's beta launch over spring break, we've had ~234 users sign up, ~7000 questions answered, ~200 questions asked, and ~130 "favorites." We've made ~11,000 match calculations. All of these numbers are growing daily and will continue to do so until the housing lottery.
We've discovered that running a node app takes a lot of hands-on management. It frequently crashes and needs to be restarted. We've been able to do a lot of work with catching exceptions which has prevented the worst of it. We've also realized how immature the platform is. The PaaS that is built in node often has its own failures. We've had pretty bad uptime, though it's gotten better recently.
I'm particularly proud of our matching algorithm which I will include here. I wrote the first pseudocode version, Seth rewrote it in proper Node.js. Then, I wrote the database integration.
var _ = require('underscore')
, mysql = require('mysql')
, connection = mysql.createConnection({
host:'[omitted]',
port:[omitted],
user:'[omitted]',
password:'[omitted]',
database:'[omitted]',
multipleStatements:'true'
});
var numMatches = 0;
connection.query("SELECT * FROM `user` WHERE `numResponses` > 5; SELECT * FROM `questionresponse`; SELECT * FROM `acceptableresponse`;",function(err,results){
//connection.destroy();
if(err){
console.log(err);
//connection.destroy();
return false;
}
process.on("exit",function() {
connection.destroy();
});
var users = results[0];
_.each(users,function(user){
user.responses = _.where(results[1], {userID:user.userID});
user.acceptable = _.where(results[2], {userID:user.userID});
});
_.each(users,function(i) {
var userMatches = 0;
console.log("-----------",i.name,"----------");
_.each(users,function(j) {
if(i.userID === j.userID)
return false;
var overlap = _.intersection(
_.pluck(i.responses, "questionID"),
_.pluck(j.responses, "questionID")
);
if(overlap.length > 6) {
var points = 0;
var possible = 0;
_.each(overlap,function(questionID) {
var importance = _.where(i.responses, {questionID:questionID})[0].importance;
possible += importance;
if(_.contains(
_.pluck(_.where(i.acceptable, {questionID:questionID}), "answerID"),
_.where(j.responses, {questionID:questionID})[0].answerID)) {
points += importance;
} else {
points -= importance;
}
});
if(possible !== 0){
userMatches++;
numMatches++;
connection.query(
"DELETE FROM `match` WHERE `userID` = ? AND `mUserID` = ? LIMIT 1; \
INSERT LOW_PRIORITY INTO `match` (`userID`,`mUserID`,`match`,`base`) VALUES (?,?,?,?);",
[
i.userID, j.userID,
i.userID,j.userID,(points + possible) / (possible * 2),overlap.length
],
console.log
);
var match = parseInt(((points + possible) / (possible * 2)) * 100);
console.log("===>",i.name + " : " + j.name + " : " + match + "%, based on " + overlap.length);//possible: " + parseInt(possible) + "/" + overlap.length);
}
}
});
connection.query("UPDATE LOW_PRIORITY `user` SET `numMatches` = ? WHERE `userID` = ?",[userMatches,i.userID],console.log);
console.log(userMatches," total matches.");
});
console.log(numMatches);Opinion Essay
Heroic investigations of life and disease have put us on the verge of a health-care revolution. Meanwhile, the software industry is booming; tech startups appear faster than you can say “medical informatics.” But at the intersection of these two complex fields lies dysfunction. Researchers and clinicians, shackled to software that no one in their right mind would use voluntarily, spend countless hours manually copying data from one system to another. And this separation of software development from clinical research is costing lives.
Juggling data
When paper records predominated in medicine, research assistants or medical students manually screened health records for certain diagnoses or laboratory values that would qualify patients for prospective clinical trials. Upon identifying suitable trial candidates and receiving their consent, researchers manually extracted the data of interest, recording the information on yet more paper. Retrospective cohort studies similarly took innumerable hours of searching health records in dusty basements. Data transfer and analyses followed.
Now, the health-care system is in the process of turning away from paper records in favor of digital storage. Research assistants toil no more in dusty basements. Research workflow, however, is stuck in an earlier century. Today's research assistants still use their eyes to screen health records, but on computer monitors rather than paper. Once consent is obtained, relevant information is typically copied by hand from the digital records onto paper, then later recopied into digital research databases.
This is a recipe for bad data. Like the children's game "telephone," in which a group whispers a sentence from one to another, the message can become garbled. In the past, this was unavoidable. Today, there is no excuse.
Time points
One consequence of this disorganization is inconsistency in when key measurements are taken. A hypothetical study might seek to determine if a specific protein level in patients' blood 12 hours after arrival at the hospital is predictive of their outcome. Researchers would compile clinical data at this arbitrary time point, including vital signs, routine clinical laboratory values, and any study-specific measurements. The problem is that none of these data are collected at exactly 12 hours. Routine clinical measurements might be taken only in the morning, for example. Even the study-specific measurements, which the researchers control, may be off for logistical reasons. Such time differences are not routinely noted in the research database, resulting in the lowered statistical power of any conclusions to an unknown degree.
Even worse, important information is often lost: data that are repetitively measured in the clinical setting, like most vital signs, are only transferred to the research database at certain intervals; data measured at in-between times are not saved. This makes it impossible to look at specific trends that could lead to new types of data analysis.
There is a better way
If clinical researchers partnered with computer experts, we could transform the way data are collected, stored, and analyzed. We could reduce human error by mandating fewer manual steps, making research faster and data cleaner. Involving programmers in clinical research could also support more advanced data structures that would allow researchers to record infinite numbers of data points and display them in simple scatter plots to identify optimal time points. And perhaps most importantly, research assistants would be free to spend more time obtaining consent from patients, reviewing literature, and looking for trends in the data, instead of acting as human ethernet cables transferring information between different computer systems and paper records, and back again.
Relying more on computer systems would also make it easier for clinical researchers to find trial participants, by screening for certain lab values in a simple database query. All that is required is commonsense application programming interfaces (APIs), established protocols that allow different software platforms to communicate. In May 2011, realizing the emerging importance of these tools, President Obama directed every federal agency to have an API. Most clinical research teams do not have any APIs, nor the programming expertise to operate and maintain them.
Finally, a more integrated system could also improve treatment. As the deluge of omics data continues, clinical researchers are becoming more and more dependent on computer software to make sense of it all. How can we gain insight from the 3 billion base pairs in the human genome when we can't effectively store and manipulate the 30-odd measures, such as blood pressure and heart rate, that we've had for 50 years?
Writing a short essay is much harder than writing a paper for school. The hardest part for me was that I didn't know what I wanted out of it when I got started. I had something that was bothering me and I thought others should know about. In the summer, I saw that clinical researchers were using computers wrong. This had implications for everyone who's ever been touched by disease. When I was talking to my mom about it, she suggested I write an Op-Ed for the New York Times. My first draft was written with that intention. It was conversational, in the first person. I showed it to a lot of people and got generally positive feedback. People felt I should indeed try to get the message out. There was no consensus on the format.
The New York Times wasn't interested in the piece. I submitted it to some medical journals: nothing. I sent it to a prior mentor: Dr. Ann Zovine. Ann is a physician researcher at UCSF. I worked for her the summer after the second year. She liked the piece and felt that it would be perfect for The Scientist.
I submitted the essay to The Scientist. They didn't get back to me for a long time. School started. I was wrapped up in teaching my web development class and going to hackathons. This paper was on the back burner. Around winter break, they finally got back to me. They liked it, but they needed some credibility behind it. They wanted me to find a coauthor and strip out some of the personal narrative.
I put out feelers and had a few people who were willing to work with me. One stood out. Dr. Martina Steurer-Muller is a pediatrics intensivist fellow at UCSF. She has a lot of experience with research and finds the computer tools totally lacking. She was happy to have her name on the paper.
The editor at The Scientist was pleased that I had found someone. But, we needed to do a complete rewrite. This was really discouraging for me at first. I wasn't sure if the piece had any power without my personal experiences. The first drafts were very weak because I was trying to keep the same skeleton without any of what made it powerful. I didn't have anything good until I started from square one.
Editing and revising this new paper with Martina and the editor took months. First, they were going to publish it only online in the April version. But then someone else at the magazine saw the piece, liked it, and decided it should be published in print in the May issue.
The most surprising thing about this process for me was how long it took. I had this idea nearly a year ago and people are just going to start reading it now. It certainly makes blogging look attractive. I think the process produced a strong paper, but I think there were certain positive qualities lost from the first version of the paper. My takeaway from this is to choose the medium of publishing carefully.
Advocacy
An Example of Advocacy
I've decided to include an email conversation I've had with my high school Biology teacher.
Zeke:
Can I ask your thoughts on an idea I've been incubating? It's not something I'm likely to do now, but it has to do with teaching kids to code and I think you might have some interesting reality checks for me.
Ben:
Sure, ask away. I am happy to play the role of reality checker.
Zeke:
Problem #1: Good web development is too expensive. Programmers are in high demand and you have to pay top dollar to get a great-looking/working site/app. Most cannot afford this, so they use simple tools without much power.
Problem #2: We as a nation (planet?) aren't training programmers fast enough. This is one of the causes for problem #1. Programming can be taught effectively to children. It just isn't. In fact, teaching programming to kids has been anecdotally associated with higher test scores in math and science. Sometimes kids get so good at coding that they are ready for professional work in high school.
Solution to both: Let's think about a company. This company would make most of its money by doing web development contracts. We would bid 30% lower than the market, ensuring more reliable employment. We might even be in the position to pick and choose our clients. This part of the company would produce significant revenue because we'd take on more projects than we could reasonably handle (hang on, I'll explain how this could ever work in a second).
The company would also interact with kids in middle school and high school. We'd do development tutoring in very small groups charging hourly. This aspect of the business wouldn't be a cash cow either, but it would pay for itself. Kids who found they liked coding could go to an intensive development bootcamp over the summer. After the bootcamp, they would be eligible for apprenticeships. Apprentices would be paid $10 / hour and work a lot. These kids would also be the ones that loved it enough to go to the bootcamp. By this time, they'd actually be pretty good. They'd be working independently. Their mentors would review their work and help them get better, but they'd actually be doing stuff. This is how the business model would work. These kids would be worth sooooo much more than $10 / hour. They'd be doing client work that would get reviewed by the staff developers.
This concept isn't that crazy. It's not unlike how doctors and lawyers are trained. The only thing that's different is the age group. I think this has the potential to shake up two industries at once: software and education.
Right now this is just a thought exercise for me. I'd like to do it someday, but I'm in no rush. I'd love to hear your thoughts.
Ben:
Hi Zeke,
Sorry it's taken me a while to get back to you, there's a lot going on at work at the moment.
Before I get into a full discussion of your idea, I have a couple of clarifying questions:
- With regards to problem one, what is the penalty for not doing anything about this? Why does it matter that programmers are overvalued and most people use digital tools without much power? This is not meant to be entirely rhetorical
- What is the current and projected demand for programmers? Where is this data coming from?
I ask both of these first because you frame your idea as a solution. I want to make sure that we agree that there does, in fact, exist a problem; and it takes the form that you have described above.
Advocacy
An Example of Advocacy
I've decided to include an email conversation I've had with my high school Biology teacher.
Zeke:
Can I ask your thoughts on an idea I've been incubating? It's not something I'm likely to do now, but it has to do with teaching kids to code and I think you might have some interesting reality checks for me.
Ben:
Sure, ask away. I am happy to play the role of reality checker.
Zeke:
Problem #1: Good web development is too expensive. Programmers are in high demand and you have to pay top dollar to get a great-looking/working site/app. Most cannot afford this, so they use simple tools without much power.
Problem #2: We as a nation (planet?) aren't training programmers fast enough. This is one of the causes for problem #1. Programming can be taught effectively to children. It just isn't. In fact, teaching programming to kids has been anecdotally associated with higher test scores in math and science. Sometimes kids get so good at coding that they are ready for professional work in high school.
Solution to both: Let's think about a company. This company would make most of its money by doing web development contracts. We would bid 30% lower than the market, ensuring more reliable employment. We might even be in the position to pick and choose our clients. This part of the company would produce significant revenue because we'd take on more projects than we could reasonably handle (hang on, I'll explain how this could ever work in a second).
The company would also interact with kids in middle school and high school. We'd do development tutoring in very small groups charging hourly. This aspect of the business wouldn't be a cash cow either, but it would pay for itself. Kids who found they liked coding could go to an intensive development bootcamp over the summer. After the bootcamp, they would be eligible for apprenticeships. Apprentices would be paid $10 / hour and work a lot. These kids would also be the ones that loved it enough to go to the bootcamp. By this time, they'd actually be pretty good. They'd be working independently. Their mentors would review their work and help them get better, but they'd actually be doing stuff. This is how the business model would work. These kids would be worth sooooo much more than $10 / hour. They'd be doing client work that would get reviewed by the staff developers.
This concept isn't that crazy. It's not unlike how doctors and lawyers are trained. The only thing that's different is the age group. I think this has the potential to shake up two industries at once: software and education.
Right now this is just a thought exercise for me. I'd like to do it someday, but I'm in no rush. I'd love to hear your thoughts.
Ben:
Hi Zeke,
Sorry it's taken me a while to get back to you, there's a lot going on at work at the moment.
Before I get into a full discussion of your idea, I have a couple of clarifying questions:
-
With regards to problem one, what is the penalty for not doing anything about this? Why does it matter that programmers are overvalued and most people use digital tools without much power? This is not meant to be entirely rhetorical
-
What is the current and projected demand for programmers? Where is this data coming from?
I ask both of these first because you frame your idea as a solution. I want to make sure that we agree that there does, in fact, exist a problem; and it takes the form that you have described above.
I could give you my thoughts now, but that might be a little premature. Why don't you get back to me about those questions above and we can continue this dialogue
Zeke:
Hi Ben,
Don’t worry about how long it took you to get back to me. I understand how busy life can be.
I’m not sure you see programming the way I do. Let me try to show you how I think about it.
Language is an intrinsic property of humans; not a technology. We make languages like spiders make webs. Deaf twins in the absence of ASL education made their own sign language as their first language. They were on track (on track!) with their language development in terms of timing. Language is really a form of telepathy. I can put an idea in your head at my own will.
Writing on the other hand is different. It’s a technology. We developed it 5 or 6 thousand years ago as a way to make thoughts timeless, to transfer to others who weren’t there. It also had the added benefit of extending memory. People could write things down like how many chickens they had…
Writing is different from language because it extends humans’ natural abilities. If you put two kids together and don’t teach them, they will likely never be literate. It’s also much harder to learn as an adult. People have decided that this technology is so important that it was included in the UN Declaration of Human Rights.
So:
Language: innate, way of transferring ideas
Writing: technology, way of transferring ideas to different times, and remembering more
What are computer languages? Even if we didn’t have computers, computer languages would be useful on paper. They are very precise ways of writing down processes. They are specific and unforgiving. But, they completely describe a way of doing something that English doesn’t (intrinsically). The awesome thing about computers is that they can take this really specific language and DO IT FOR YOU! Every year we do more with computers. We communicate with them. We bank with them. We remember with them. We meet people. We even use them to think in ways that we aren’t inclined to, say, analyzing millions of records in a database…
Why are programmers in such high demand? There’s a computer in every office in much of the world. There are computers in most people’s pockets. We have this fantastic foundation for so much. But, very, very few know how to build.
I’m not saying we should replace learning to read with learning to code; that’s crazy. I’m just saying that it’s not even offered in most high schools. They have computer classes, just not coding classes. This is crazy. It’s also pretty crazy to insist that kids memorize the Pythagorean theorem, the Krebs cycle, and have no understanding of the backbone of modern math and science: computers. For more on this: Code.org Video
Also check out this infographic that cites the Bureau of Labor Statistics, the College Board, and the Association for Computing Machinery: Code.org Stats
Ben:
Hi Zeke,
Thank you for explaining your thoughts in more detail. I think you make a compelling case for the importance of programming skills and the potential for integrating them into education more broadly. Here are my thoughts:
- I agree that there is a significant value in teaching programming to kids. It equips them with a new form of literacy that is increasingly relevant in our digital world. The analogy to language and writing is particularly striking.
- Addressing the demand for programmers is indeed a critical issue. The data you’ve provided shows that the demand is growing and that we’re not keeping up with it. This mismatch creates opportunities for initiatives like the one you proposed.
- Your idea of a company that combines web development services with educational programs is innovative. It leverages the high demand for programming skills to create a sustainable business model while also addressing an educational gap.
- One potential challenge is ensuring the quality of education provided to the students. You’d need a strong curriculum and experienced mentors to guide them effectively.
- Another consideration is the scalability of the model. How would you ensure that the educational component can be scaled up to reach more students without compromising on quality?
Overall, I think your idea has a lot of potential. It addresses real problems in both the software industry and education, and it could have a significant impact if executed well. I would be happy to continue discussing this and help you refine the concept further.
Conclusion
I predict that when we look back we will see the early 21st century as an unusual time. Computers have become commonplace. Most aspects of our lives have been transformed by their presence. Yet, most people don’t have the ability to harness their true power.
Often organizations conclude that they can’t build their own computer systems. They hear about tech companies hiring hundreds of programmers and paying them well. But organizations can’t ignore computers either if they want to interact with the world. Organizations feel forced to use “canned goods”—computer tools that are supposed to “work” out of the box. I put “work” in quotes because they don’t really. They serve the lowest common denominator and take away many of the intrinsic benefits of computing. They don’t share data well. They don’t promote structured thinking (or data). One example of this is covered in detail in my opinion piece. I don’t feel the need to add more detail here.
My Div III shows that there’s another way. I worked with (mostly) non-techies to build “empowerment software.” I showed that it’s possible to build web services that make a huge difference quickly and (relatively) cheaply.
Much of the work done at tech companies is handling problems of scale. If Facebook was built to serve 1000 people, it would require a fraction of the development power, even with the same feature set. The problems these organizations face typically don’t need to be brought to millions. They can hire just one developer. If they did, a whole slew of new possibilities would be open to them—improving efficiency and quality of work.
In fact, empowerment software is getting easier and easier. More and more services are open to small developers. Twilio is a great example of this. It lets someone with basic programming ability write web apps that can make and receive phone calls and text messages.
But, more work is needed. There aren’t enough programmers. This makes even hiring one too expensive for many. If you ask me, something this important to society should be taught in every high school. At least basic competency should be a requirement. Changes like this would empower countless people and organizations to live better.
- Next: Await... async