Cost of computing
Before we talk about the cost of computing, let's talk about the cost of computers.
I did a comical estimation with Claude on the cost (in todays dollars) for the CPU time that would have been required to load a web page in 1960 if the web had existed. It was $3,800. Today the same web page can be rendered for $0.00000006.


Credit to Steven Pemberton for this comparison
But, it's not just computers. It would have cost more than $10k (in today's dollars) to light your home for a day several hundred years ago.
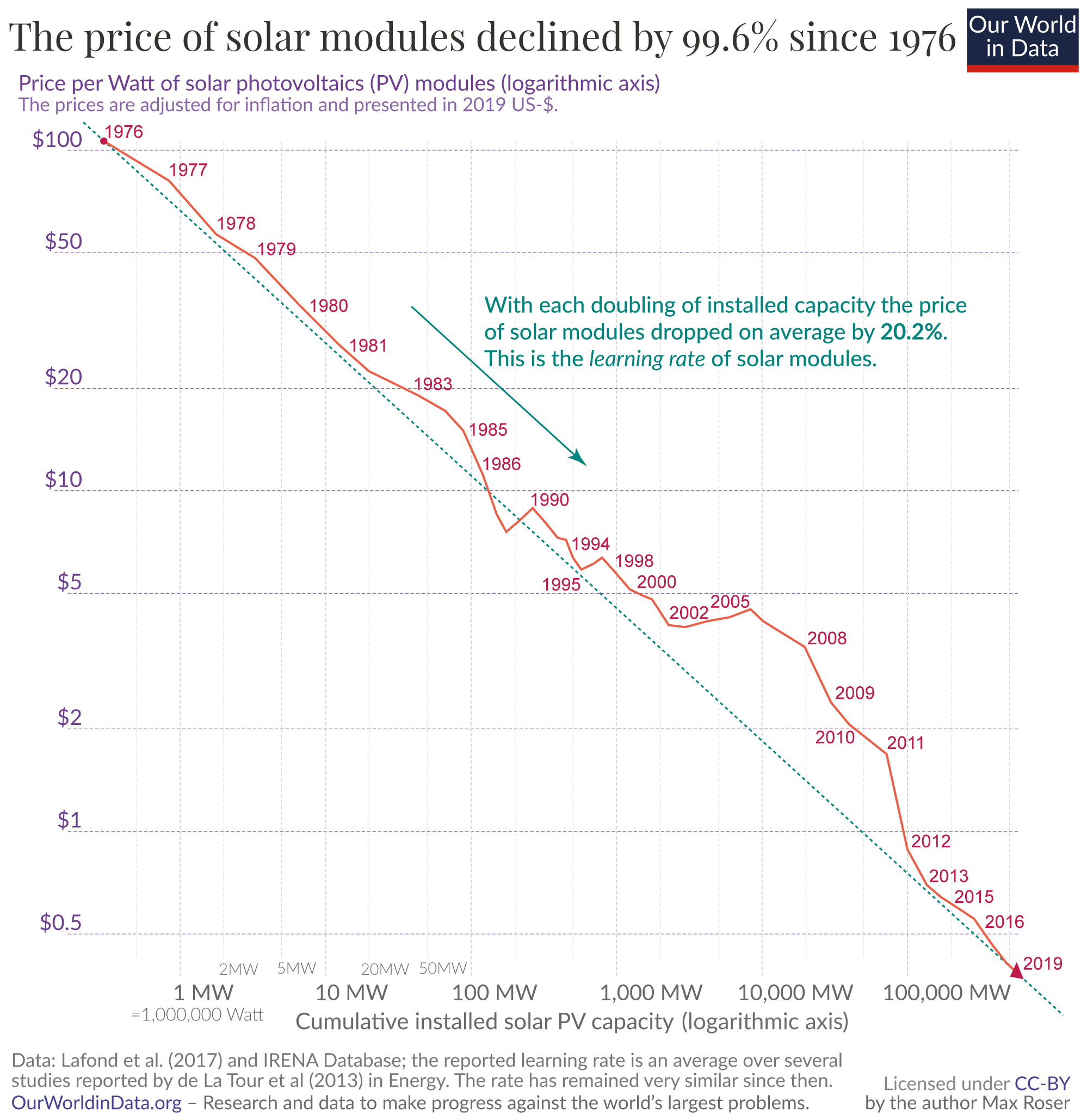
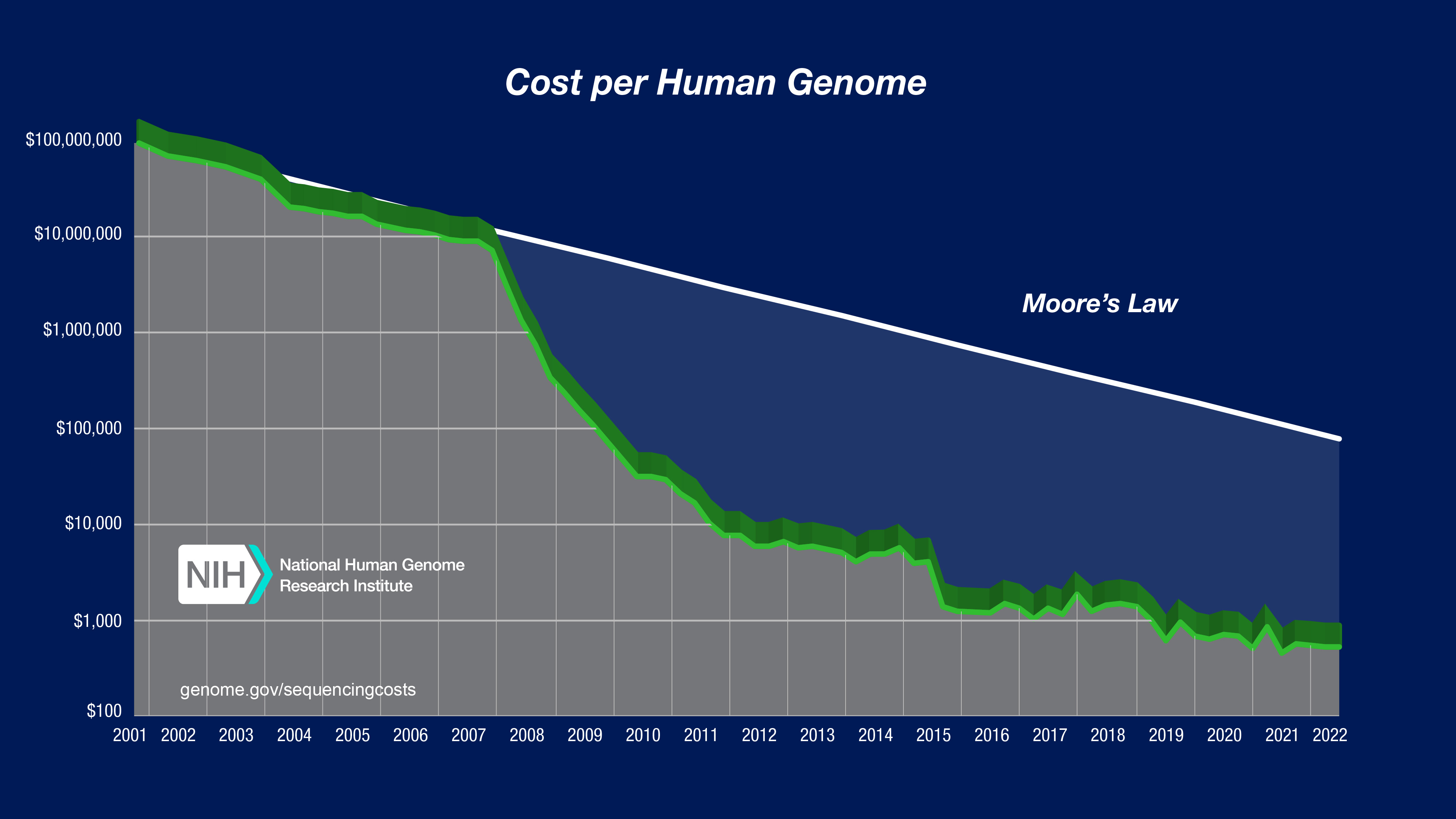
We accept that prices change throughout history, but the sheer magnitude of the decline in technology prices is staggering. People in general are not great at contemplating non-linear changes[1].
The Experience curve effect is a pattern that shows up repeatedly in technology. As people learn, they get more efficient. They drive down errors by improving processes. Supply chains are optimized. Then, second order effects start to happen. As prices drop, markets grow. Purchasers who were recently priced out are start buying. That allows economies of scale come into play.
Efficiencies compound. If you take a nap for a decade or two, numbers can get very very 🤏. Entrenched market dynamics that were once a given become a historical footnote. For example, it's not uncommon to hear people marvel at the fact that computers used to take up entire floors of high rises. Go to cocktail parties and start listening for the word "before." The internet before the web. Personal computers before GUIs. Solar. Light. DNA Sequencing. Aviation. Automobiles. Batteries. The list goes on and on.
Inflection points
Experience curves follow a nice predictable path until they don't. At some point the curve breaks. And when it does, it happens in one of two ways.

Plateaus
Plateaus occur when some kind of local minima is reached. For example, people have been saying we're almost at the end of Moore's law for my entire life. Even Gordon Moore predicted that Moore's law would end at some point. At some point the laws of physics impose their limits. You can't really make a transistor smaller than an atom.
"Earthquakes"
Sometimes the set of forced governing the experience curve suddenly change. This could be a technological innovation, government intervention, or even ecological or economic or cultural change. Whatever the cause, when a new dynamic takes effect, prices can change even more suddenly than an Experience Curve.
In the case of whole genome sequencing, an inflection point occurred when Massive Parallel Sequencing replaced Sanger Sequencing. It took this technology years to get to market, but once it did, the Experience Curve broke and a new one formed.
It's hard to appreciate what this can mean for society. Every time we pay for something we're deciding not to pay for something else of the same price.
I asked Perplexity to help me come up with something else society could have done with the money it would cost to sequence one person's genome over the last 24 years.
| Year | DNA Sequencing Price/ person | Something else society could have done with the money |
|---|---|---|
| 2001 | $100,000,000 | Expansion of a (non-US) public transit system (e.g., Metro de Los Teques in Venezuela)[2] |
| 2006 | $10,000,000 | Renovation of a public library branch[3] |
| 2008 | $1,000,000 | Installation of a traffic management system[4] |
| 2011 | $10,000 | Purchase of a police patrol vehicle[5] |
| 2015 | $4,000 | Installation of playground equipment[6] |
| 2020 | $1,000 | Purchase of a commercial-grade AED[7] |
Different things are possible when something costs $10^8 than when they cost $10^3.
What about the cost of writing programs?
When I say "cost of computing," what I mean is the units of effort are required to express one unit of computational thought to a computer. We can sort of think of that as a price... And in many ways it is. Sometimes it's a cost in literal ways: it's an input to the cost structure of any organization employing software engineers. Sometimes it's a cost in less literal ways. When the cost of expressing computational thought changes, the ambitions of my side projects change because it's suddenly possible to do more.
For the last couple decades, while I've been a programmer, and until quite recently, the cost of computing has been in a plateau. Programming is different than it was in 2003. Programming is better than it was in 2003! But, (again until recently!), programming is not cheeper than it was in 2003, in my opinion.
But, historically, we know that at one point writing programs used to be more expensive than it is today. There was a time, for example, when programs were written on punch cards! For ages programs were expressed in assembly. It's unclear to me when the price started to stagnate.
The predominant UI for programming has been a bunch of text files in folders that get compiled down to something deeper. It's been a long time since a really radical programming idea has gained wide-spread adoption and created a new dynamic. I'm not talking about some neat programming language. I'm talking about a different way of thinking about what a program even is. One I can think of is the Spreadsheet.
Have you ever seen a spreadsheet expert at work? It's magical. Spreadsheets–when leveraged to their full potential–let the programmer construct elaborate computational models. They're live and reactive, not text files. Data visualization is built in. The learning curve is smooth. I think that a smart novice could start with recording tabular data and get them self to Monty Carlo simulations in about a month.
And they took over every industry. Every organization I've interacted with is dependant on an intersticial network of inconsistently maintained spreadsheets. I'd like to know if there's a single organization today that is not run this way.
Spreadsheets are so good that even when Microsoft made their UI hideous for a couple decades, they still took over the world.
I'm not aware of any programming environment since spreadsheets that have as fundamentally altered the cost of composing programs, and none that have enjoyed widespread adoption.
It's worth taking a beat to appreciate what I just said. How is it possible that the last major inflection point in computing's cost curve happened in 1979 on an Apple II?
Of course you can't run web servers in spreadsheets. You can't build Sim City in spreadsheets. Spreadsheets aren't even turing complete without some scripting language. So while spreadsheets altered the cost of computing radically, on their own, they were limited to a certain category of program.
This visualization was created using v0.dev
What are the factors that contributed to the success of spreadsheets? Here's my list.
- Very low barrier to entry. They produced value for all users, regardless of technical background.
- Everything is a cell. One abstraction to encapsulate both data and code. When you reference a cell, you don't care if it's a data cell or a code cell. It's a cell.
- Runtime === buildtime === prod. This thing is live! You didn't need to understand or debug some pipeline to get the thing to do something. Just open a file and you have the real thing.
- They were playful! Just edit a cell and everything reacts.
Let's contrast this with Smalltalk

Smalltalk was is awesome. Admittedly, as a 90s baby, I never really got to play with it in it's heyday. While Smalltalk never really broke out into mainstream society (ask the normies in your life about it, they'll blink at you), it'd be crazy to call it a failure. It's influence on programming writ large cannot be understated.
- Smalltalk was the first truly object-oriented programming environment.
- And the first instance (correct me if I'm wrong) of a programming environment running the program and giving the user feedback (like spreadsheets!).
- It was alive–no build step.
- Everything is an object. One abstraction to encapsulate everything from data to code.
The UI influenced modern operating systems and IDEs. In 1979, Steve Jobs famously ripped off the Smalltalk UI for Lisa when he was shown it running on the Xerox Alto computer.
While spreadsheets and Smalltalk were both reactive programming environments, Smalltalk just was just too expensive to be viable as an end-user programming environment. One of the project's stated goals was to be approachable to children. It wasn't. If it were, more children would have used it.
In order to use Smalltalk, you had to write code. Code takes effort to read and write. It's fickle. Humans, for the most part, struggle to reason about it without experience. Unlike a spreadsheet, you can't just open up Smalltalk and fuck around and find out–at least not without a lot of effort.
Both Smalltalk and Spreadsheets are governed by a single abstraction: For spreadsheets, the cell, and Smalltalk the object. One reason for the success of the spreadsheet is that it's single abstraction was tangible to a novice user. The building block of the whole damn thing had a UI.
Hypothesis: we can predict the success of a computing environment by judging the quality of the abstractions and the quality of their UX.
Before LLMs, which I'll get to, the last time I got excited about a piece of technology maybe breaking the Computing Experience Curve was in 2013 or 2014 when I tried Airtable. Airtable took a powerful software pattern–the relational database–and put a next level UI on top. High quality abstractions. High quality UX.
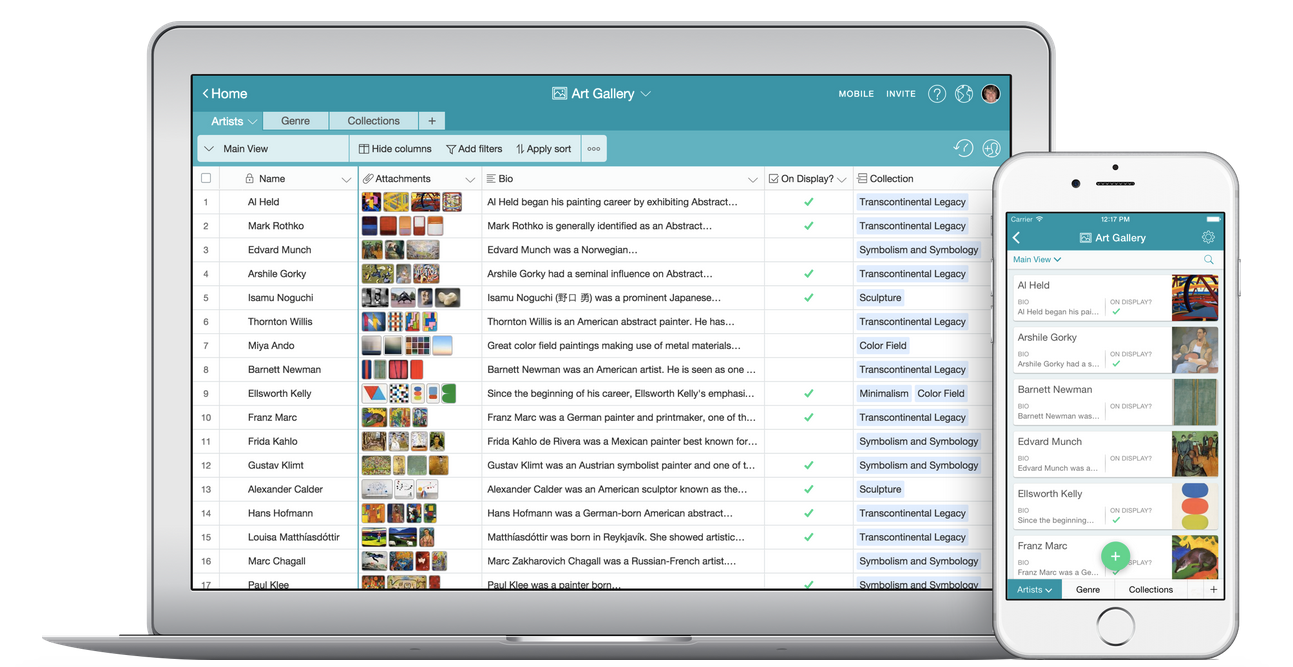
Airtable showed so much promise. Everyone already used Google Sheets as a makeshift database - sharing lists where each row followed a consistent structure of columns. The familiarity of spreadsheets made it easy for anyone to contribute data and leverage formulas. But spreadsheets weren't built to be databases, even if you could awkwardly force them into that role. But, it was the best tool for the job because there was no one[8] in the market making an end-user facing database that made any sense.
The abstractions of a relational database (tables, rows, types, relations, constraints, etc) are more complex than the abstractions of spreadsheets. But, I thought that Airtable's UI was so good that maybe it could effectively teach novice users how it worked through experimentation. It seemed a hell of a lot easier than anything else out there.
erDiagram
ARTIST {
int artist_id PK
string name
string nationality
string birth_year
string death_year
text bio
}
ARTWORK {
int artwork_id PK
int artist_id FK
string title
string year_created
string medium
string dimensions
string image_url
boolean on_display
}
COLLECTION {
int collection_id PK
string name
string description
date creation_date
}
GENRE {
int genre_id PK
string name
string description
}
ARTIST_GENRE {
int artist_id FK
int genre_id FK
}
ARTWORK_COLLECTION {
int artwork_id FK
int collection_id FK
date added_date
}
ARTIST ||--o{ ARTWORK : creates
ARTIST }|--o{ ARTIST_GENRE : belongs_to
GENRE }|--o{ ARTIST_GENRE : has
ARTWORK }o--o{ ARTWORK_COLLECTION : included_in
COLLECTION }|--o{ ARTWORK_COLLECTION : contains
Airtable took a leap of faith and trusted that the bigger market would take the time to learn the way Airtable worked. And in return, Airtable created a set of well designed, well thought out, inviting power tools. They had a generous free plan so people like me could try it (and then advocate to use it at work).
And people like me loved it.
I used Airtable to run my wedding's invite and RSVP system. I used Airtable to build #walkthevote in 2020. For our wedding, we had tables like households, invites, rsvps (which had dietary preferences), gifts (for keeping track of thank yous). We had almost everyone's cell phone number, but we didn't have a lot of physical addresses. I wrote a web service to text everyone and have a dialog with them to gather their address and insert it into the address table.

Unfortunately for Airtable, Inc, while their UI is awesome, it's not awesome enough to make this concept understandable to a novice user before they give up. Some users embraced the tool and put in the work to learn it. But that market just wasn't nearly as big as Airtable, Inc had hoped. To be clear, Airtable is a successful company, and if you ask them, they'll tell you that it's awesome that they've sold into so many fortune 500 companies. But they are not on track to become a verb, change the cost curve of computing. They're "just" normal innovation.
One afternoon in August, I remember nearly doing a spit take when trying out a new thing from Supabase.
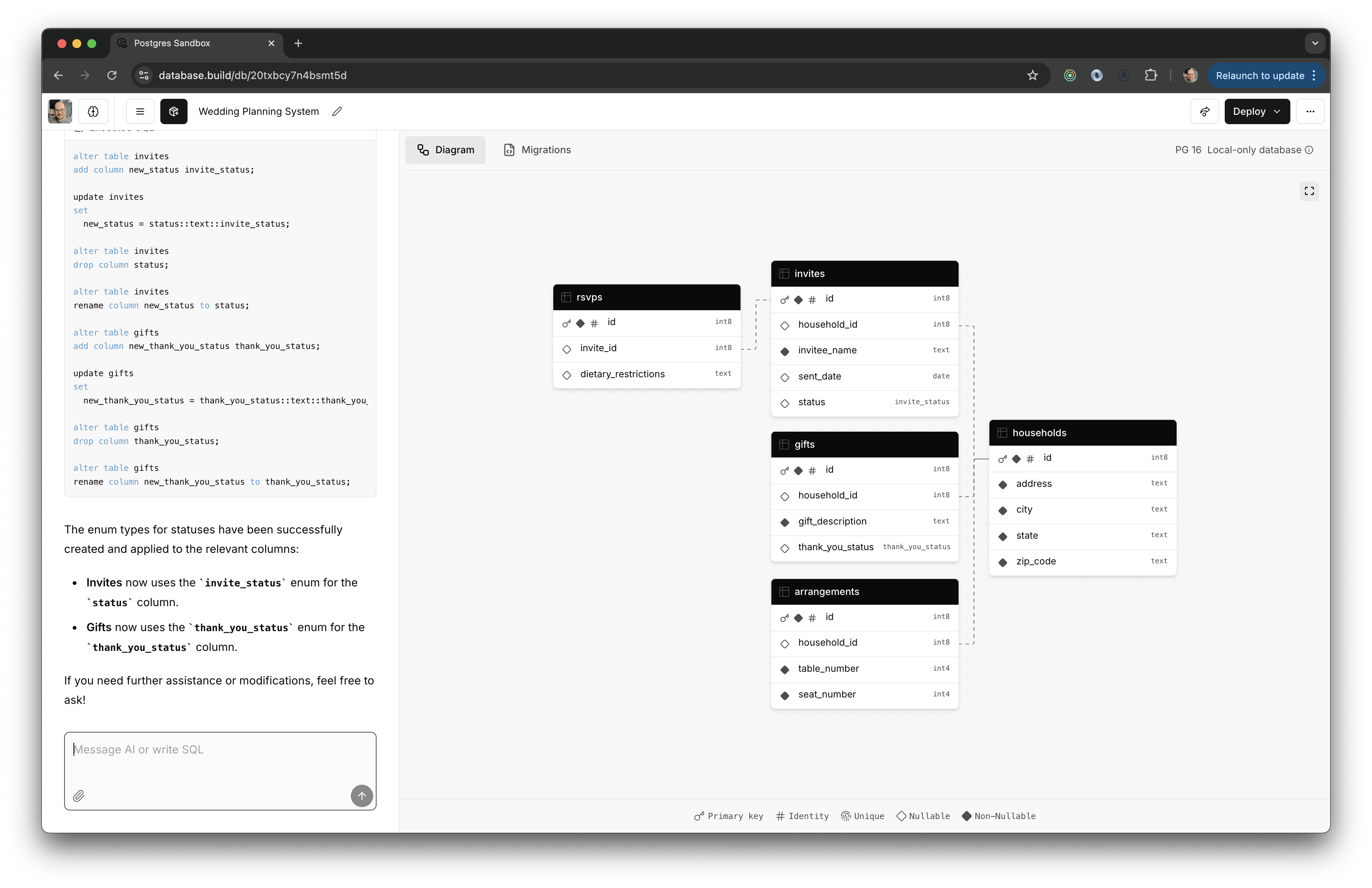
So we're finally getting to LLMs.
☝️ This thing (called database.build but previously called postgres.new) is so fucking cool.
It's exactly what Airtable was missing in their first-time UX.
On some level it's "just" another browser-based agentic code generators not unlike Claude Artifacts or OpenAI Canvases or V0. In all of these cases, a runnable artifact is produced and evaluated as you chat back and forth with the LLM. But with database.build, the code takes a back seat in the UI. Instead of reviewing code, you review a pretty sick diagram made with react-flow.
Database.build runs a real postgres database inside the browser with pglight. If a DDL statement produced by the LLM doesn't work in the real database, the LLM gets that feedback and tries again. It's typically able to self correct. If you had asked me in 2016 when this kind of technology would come to the market, I would have said "never."
Here's basically how database.build works:
flowchart LR
User((User)) -->|"Natural Language Request"| LLM
LLM --> DDL[SQL DDL]
DDL -->|"Generate visualization"| Diagram
Diagram -->|"Reviews"| User
subgraph WASM[WebAssembly Runtime]
DB[(Postgres)]
end
DDL -->|"Execute"| DB
DDL --> LLM
linkStyle 0,1,4 stroke:#e74c3c,stroke-width:2px;
linkStyle 2,3,5 stroke:#2ecc71,stroke-width:2px;
There are two general categories of cost when developing software: reading code and writing code. Here You write in english and you read a diagram. When things get off the rails, you can open up the DDL and fix it.
In the future, the user might not need to know about the DDL at all.
I wouldn't be surprised if Supabase ends up being the company to build the first database that the normies actually start using, although that doesn't seem to be their mission. Airtable tried to make creating a database easier by building fancy point-and-click UI. Supabase is making it easier by using an LLM (which, to be fair, wasn't available to Airtable when they started). Their core units of abstraction are the same, but their presentation and interaction layers are totally different.
Hypothesis: One big reason this thing works as well as it does is because of it's constraints. There are only so many things that are possible in a relational database! Contrast this with V0/etc. The universe of possibilities is far far wider, and that makes it harder to get just right. It also limits what's possible with database.build. You can't build a 3d visualization in a database, after all.
None of the projects I've talked about thus far are "real" programming environments. They're all toys. You can use them to build impressive stuff, but you don't maintain real Big Kid Software (todo: trademark "Big Kid Software"). in them. Of course.
That brings me to another pattern that's very hot right now: IDE + AI. Examples include Cursor, Zed, Copilot and more.
Cursor is an interesting case that I should discuss briefly. I use it. It's good. Quite good, even. It's kind of incredible that they've continued to lap microsoft over and over again using their very own open sourced IDE as a foundation. Copilot, Microsoft's version, started first but somehow seems to be constantly playing catch up. It's not bad, it's just not as good as Cursor.
All these IDE + AI apps are examples of AI veneer. Take a product that's already good, slap some AI on top. There's nothing wrong with veneer. Veneer is nice. You can improve a product with AI veneer. You can even improve it a lot! You can probably use AI veneer to reduce the price of programming by some meaningful amount. But. I promise you it is a trap headed to a plateau. These apps are going to make it possible for product managers to make really cool prototypes. They're not going to change the nature of software.
It'd be a tragedy if in the 2060s we were still coding in text files on little screens with keyboards and LLMs.
We are having a mental cache invalidation event and we need to revisit our priors. Every programming environment idea we've ever thought of that was "awesome but impossible" or "science fiction" deserves another look. Having fuzzy (even flawed), intelligent building blocks in our computers opens up the possibility for a truly different programmable medium.
Of course there are people working on this. Lots of them. I know some. The folks at TLDraw are doing some really interesting stuff. In theory they're a collaborative whiteboard company. And their flagship product is quite good. But they seem quite preoccupied with thinking about computing and computational media. In 2023 they made MakeReal, a tool that let users draw a UI mockup and get a working prototype–sort of like V0 but without text prompting. Then recently they announced TLDraw Computer
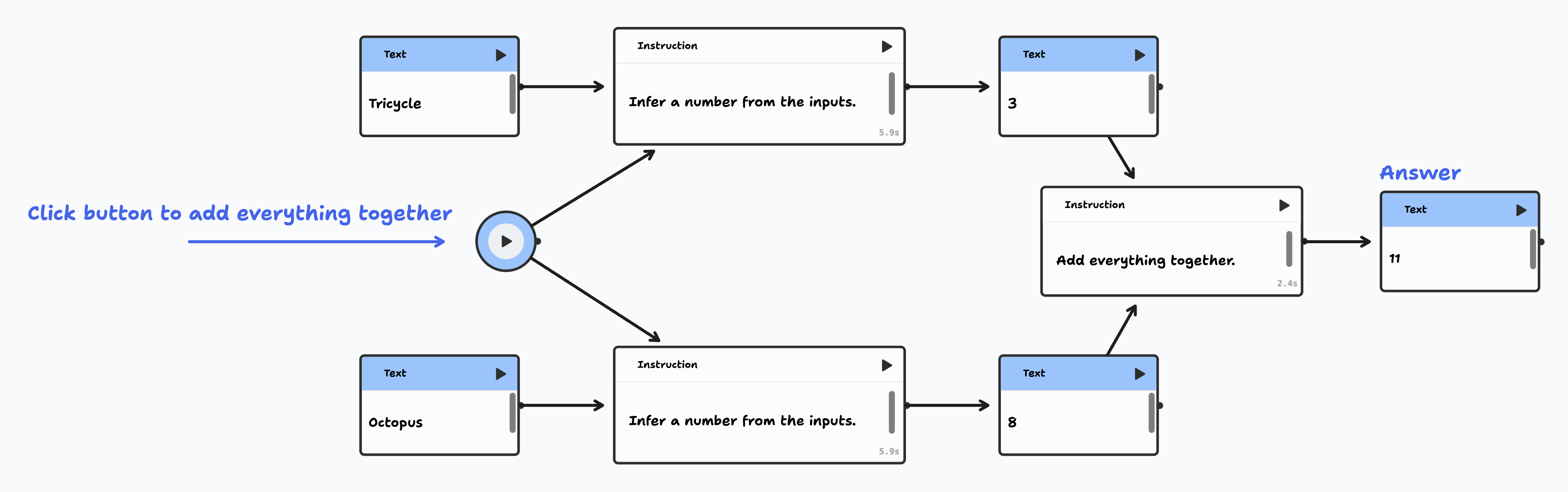
I'm not saying we're all going to be writing programs in TLDraw Computer in several years. I don't think TLDraw is saying that. I don't think you could write TLDraw in TLDraw Computer. But. They are doing the work. They're rethinking the foundational assumptions. And I'm really eager to see what's next.
I think we very well might be in an inflection point in the Efficiency Curve. We probably are. The question is, how low will we go. If we stop at AI assisted coding, and lose sight of the dream of AI assisted programming, we're at risk of getting caught in a disappointment local minima. Instead, I'd like to see a programming environment that
- a few high quality, powerful core abstractions
- very very good deeply intelligent UX on top of those core abstractions
- Is not a toy - you should be able to build modular units and hide complexity
- Is visual: end user sees and manipulates some visual representation of the program, not just code
- Exposes contracts and types as a first-order - we haven't really touched on this but it feels important
- Semantically searchable: "find where we make the api call to X" should be as easy as grepping
- Local first (a guy can wish right?)
- Fast (goes w/ the above)
- Fun
this post is still under construction
scrapbox

| Spreadsheets | Smalltalk | Conventional Coding | Airtable | Database.build | TL Computer | |
|---|---|---|---|---|---|---|
| Core Abstraction | Cell | Object | ... | Table/Relation | Table/Relation | Node |
| Core Abstraction UI Quality | ||||||
| Instant Feedback | ||||||
| Entry Barrier | ||||||
| Complexity Ceiling | ||||||
| Scale Ceiling | ||||||
| η Ratio (Effort/Thought) | ||||||
| Domain Limitations |
stuff to weave in
- https://river.maxbittker.com/
- Making good software requires taste, craft, prioritization. Making software that changes the world requires new abstractions.
- Obsidian
- Dynamicland
airtable evil?
I can't talk this much about Airtable in a blog post without telling you that... they might be evil.
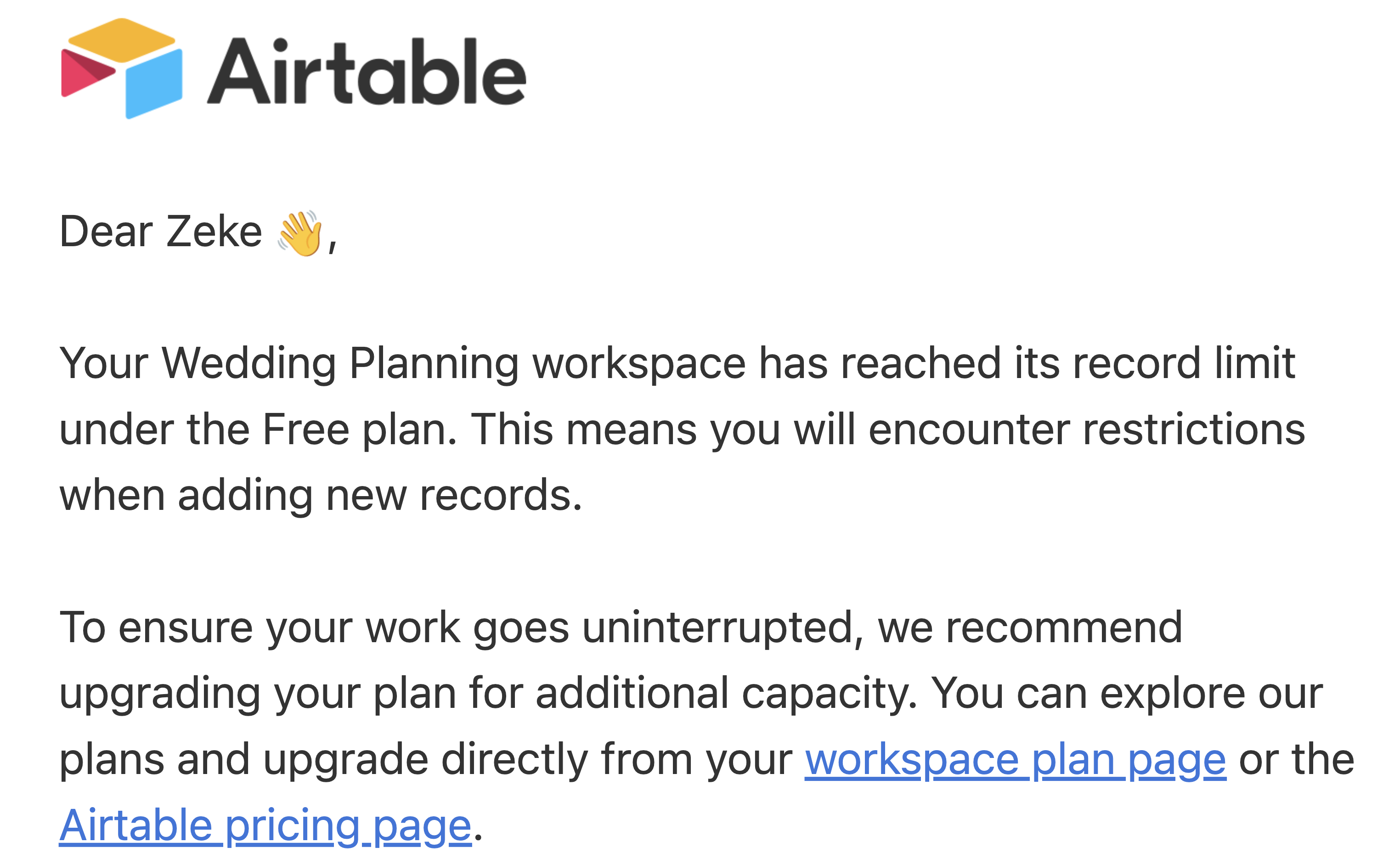
Recently, when I needed to access our wedding Base on Airtable, I was warned that since the last time I had used it, a new artificial row limit had been imposed of 1000 rows. That's insane. And stupid. If you're going to build a personal computing tool, and you're going to offer a free version to consumers, then you need to be able to plan a wedding in. I get charging companies for SAML integration, auditing and collaboration tools, support, etc. Makes perfect sense. Don't offer consumers a free plan if you can't plan a wedding in it. It forces last minute Saturday sqlite migration scripts. And that's annoying.
And. If you're going to impose a stupid, pointless row limit, you gotta let our existing bases keep working.
OK. That might be enough ripping into Airtable. They're still cool. But I'm not using them anymore. If you're looking for recommendations, try Baserow or Nocodb. Or, just use sqlite.
Exponential Growth Bias is the formal term for the phenomenon that humans seem to understand and predict linear changes far easier than exponential ones. It's why people had a hard time accepting COVID at first. How could ~30 turn into millions so quickly?? ↩︎
In 2001, $100 million was allocated to the Metro de Los Teques project in Venezuela to expand public transit and connect Los Teques with Caracas. Source: CAF Development Bank Report. ↩︎
The Seattle Public Library renovated its Yesler branch in 2006 for $6.8 million as part of its "Libraries for All" bond issue. Source: Seattle Public Library Renovation. ↩︎
Advanced traffic management systems cost between $500,000 and $4 million. For example, the I-90 Active Traffic Management system in Washington State cost around $12.9 million in 2010. Source: Washington State DOT Report. ↩︎
Police patrol vehicles typically cost around $10,000 to $12,000 per unit in 2011. Source: Rio Rancho Police Capital Improvement Plan. ↩︎
Playground equipment costs vary but individual pieces can range from $3,000 to $5,000. Source: Playground Equipment Cost Estimator. ↩︎
Commercial-grade Automated External Defibrillators (AEDs) typically cost around $1,000 to $2,500 today. Source: AED Superstore Pricing Guide. ↩︎
There were some other end-user-facing databases. One I remember messing around with as a kid was Microsoft Access. I have a vague memory from the 90s of my mom working on a DOS database with my dad as they set up the infrastructure for her Greeting Card business. None of these technologies enjoyed widespread adoption, though. And it felt like Airtable really could. It had mobile support. It had tons of cool web tools. ↩︎
- Next: How to help a student get unstuck
- Previous: Playing with Hilbert